Services in arXiv NG¶
This section describes the internal architecture and implementation parameters for arXiv-NG services.
A demo arXiv-NG service can be found at https://github.com/arxiv/arxiv-zero;
the arxiv-zero project is referenced throughout this section.
Micro or Meso¶
The general strategy for transforming arXiv from a monolithic architecture to a services-based architecture is to break the classic system into smaller parts that are easier to describe and reason about, and that can evolve independently as the project proceeds.
Often a service will be concerned with a single resource or a cluster of closely related resources, and/or will provide a specific process or transformation of a resource. For example, the plain text extraction service is responsible for extracting plain text content from PDFs (process), and making that plain text extraction (resource) available to other parts of the system.
Services in arXiv-NG will not always be “micro”. Going too small can introduce new costs, e.g. increased complexity, increased I/O. The submission & moderation service (the core of the submission & moderation subsystem) is an example of a “meso” service; it provides a variety of interfaces for submission- and moderation-related activity concerning submissions and related resources.
Internal architecture & Flask implementation¶
arXiv-NG services are implemented in Python 3.6 using the Flask web microframework.
The internal architecture of arXiv-NG services focuses on separation of concerns, clarity, and testability. It is modeled loosely on the onion and hexagonal architectural models, with some pragmatic (but conscious!) deviations.
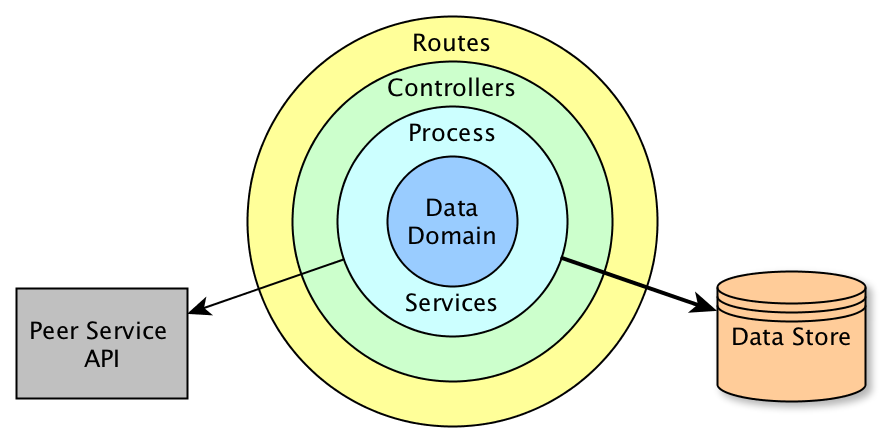
Fig. 26 Onionized internal architecture of NG services. In the onion model, outer modules can depend on inner modules, but not the other way round. The services modules are responsible for integrations with data stores and peer services.¶
One such deviation is that we embrace the fact that we are implementing applications using the Flask microframework. Whereas pure adherence to the dependency inversion principle would have us design the application such that the web framework were external to the core of the application, in our case we will take advantage of Flask goodies in multiple layers of the application, taking care to contain dependencies for maximum testability.
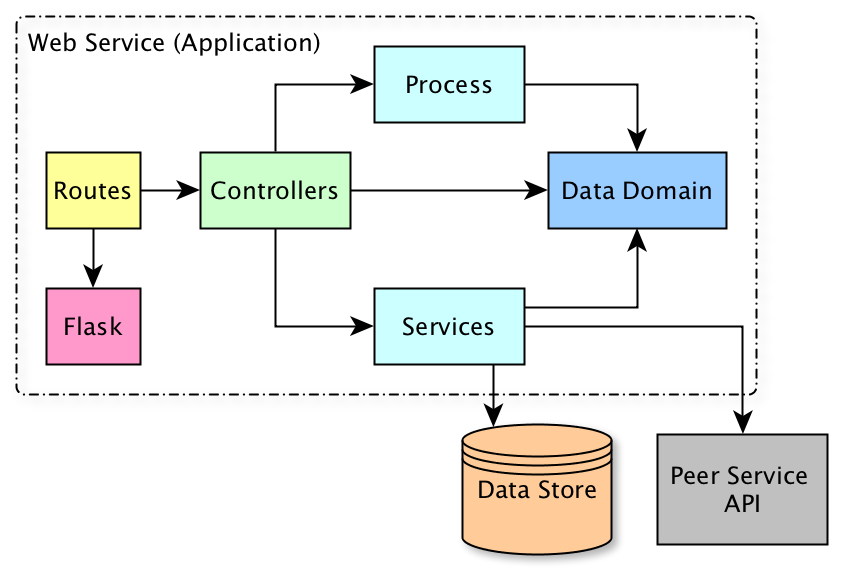
Fig. 27 Flow of control/dependencies in the internal architecture of NG services. The routes modules provide integration with Flask routing, request/response mechanisms, serialization, and call controllers. Controllers orchestrate work by process and services modules by passing around objects defined in the data domain, and generate response content.¶
Typical project structure¶
A typical application will be organized something like what is shown below.
Simpler apps may have more or less nesting; e.g. the domain module may just be
a single domain.py file, whereas a service with many parts (e.g. ORM
integration with a database) may have many submodules. Files are shown in order
of the sections of this document, below.
application/
├── domain/ # The domain defines core concepts, rules, and
│ ├── __init__.py # interactions handled by the service.
│ ├── conceptA.py # We have a rich domain in this app, so we use
│ ├── conceptB.py # submodules.
│ └── tests/ # These tests will exercise methods/properties on
| ├── __init__.py # the domain classes.
| ├── test_conceptA.py
| └── test_conceptB.py
|
|
├── services/ # Services should accept and return domain objects.
│ ├── __init__.py # They should screen off the underlying technology.
| ├── store.py # This is a simple service, so only one file.
│ └── tests/
| ├── __init__.py # Mocks are useful for testing services.
| └── test_store.py
|
├── controllers/ # Controllers do the work of handling requests,
│ ├── __init__.py # using the domain and any needed services.
| ├── operation_a.py # They can be split up into submodules if there
│ ├── operation_b.py # are many of them.
│ └── tests/ # These tests involve passing request parameters to
| ├── __init__.py # the controllers, and evaluating their returns.
| ├── test_operationA.py # Services should be mocked.
| └── test_operationB.py
|
├── routes/ # Routes use Flask Blueprints to map HTTP URLs and
│ ├── __init__.py # methods to controllers.
| ├── api.py # Some apps provide both APIs and user interfaces,
| ├── ui.py # so we use submodules.
| └── serialize.py # Additional sub/modules can help with interpreting
| # requests and serializing responses.
|
├── config.py # Flask application configuration.
├── factory.py # This module provides factory functions for making
| # new apps, and wires up things like middleware,
| # error handlers, and other goodies.
|
├── templates/ # Jinja2 templates go in here.
| └── application/
| ├── base.html # Usually an app will have its own base template
| | # that extends the base/base.html template in
| | # arxiv.base.
| └── some.html # Additional templates inherit from the local base
| # template (e.g. application/base.html).
└── static/ # Static assets go here.
. ├── js/
. └── css/
.
schema/ # If the app has an API, it should have a schema.
├── openapi.yaml # The OpenAPI schema describes the API operations.
└── resources/ # It refers to JSON Schema documents, which
. └── resourceA.json # describe the resources handled by the API. These
. # may or may not map directly to domain concepts.
.
app.py # Used by the Flask development server.
wsgi.py # WSGI module used in production.
uwsgi.ini # Configuration for uWSGI application server, used
. # to run the app via wsgi.py in production.
Dockerfile # Describes the runtime for the application.
Domain¶
The application domain provides data structures that describe the main concepts, relationships, and rules that are within the scope of the service. These are usually classes or types.
The domain should:
Provide classes or other structures/descriptors that define the shape of the main data concepts within the service.
Define any critical rules or properties based on the state of domain objects.
The domain should absolutely should not:
Depend on any other module(s) within the application.
Implement or encapsulate any I/O or persistence concerns (use a service module for that).
Be shared among services, unless services implement or rely on core concepts and logic that must be identical.
Implement de/serialization (e.g. from/to JSON, XML).
Some useful tools for building the domain:
NamedTuple; these are quite performant, and (generally speaking) immutable.
Data Classes; but be warned that there is some overhead that can add up if you are working with hundreds or more objects in one thread.
The objects or classes in this module can be imported and used by the process, service, and controller modules.
Process modules¶
Process modules are an optional component that define use-cases and other business logic of the application on top of the domain. Simpler apps may not need process modules, e.g. if their main operations (on top of the domain) are fairly simple and are easy to reason about in the controllers.
Each process module exposes an internal API, generally a set of functions representing the use-cases supported by the module.
The functions or methods exposed by each module should accept and return only native Python types and/or data objects defined in the Domain.
To facilitate testing, process modules should generally be framework-agnostic. Process modules are imported and used by the controller modules.
Process modules should:
Use objects/classes from the service domain modules;
Implement use-cases and features, especially those that involve transformations of state.
Process modules should not:
Implement I/O or persistence concerns;
Depend on services or controllers.
Service integrations¶
Service integration modules provide integrations with external services, including databases. Each service module is concerned with a single external service, and provides an API (generally a set of functions) for use by the controller modules. The functions or methods exposed by each module should accept and return only native Python types and/or data objects defined in the data domain modules.
Service modules may attach configurations and sessions (e.g. database connections) to the Flask application. Some examples of service modules:
A service module used to talk to the plain text extraction API from submission applications can be found here. It uses the base API integration class to do application configuration, context management, and error handling.
A simple database integration using Flask-SQLAlchemy can be found in the submission agent.
Controllers¶
Controller modules are the primary point of control for application execution. These modules orchestrate processing in response to request data, using the domain <data-domain-modules>, any processes, and performing I/O via services.
A controller module contains public functions that comprise an internal API for use by the routes modules.
Controller modules may make thoughtful use of Flask utilities and helpers,
taking care not to undermine isolation for unit-testing. The Flask request
proxy object, however, should not be used directly here; interaction with the
client request is the responsibility of the
routes modules.
An example controller function:
from typing import Tuple
from http import HTTPStatus
from werkzeug.exceptions import NotFound, InternalServerError
from application.services import storage
HTTPResponse = Tuple[dict, HTTPStatus, dict] # Data, code, headers.
# Note the use of Numpy-style docstrings, below.
def retrieve_something(document_id: str) -> HTTPResponse:
"""
Retrieves a something by its document ID.
Parameters
----------
document_id : str
Identifier of the requested something.
Returns
-------
dict
The requested resource.
int
The HTTP status code for the response.
dict
Headers to add to the response.
Raises
------
:class:`NotFound`
Raised if the requested resource does not exist.
:class:`InternalServerError`
Raised if there is an unrecoverable problem accessing the storage
service.
"""
# Most services provide a class method called ``current_session()`` that
# gets/creates an instance of the service specific to the request
# context.
service = storage.SomeService.current_session()
try:
data = service.get_a_thing(document_id)
# Services can raise their own specific exceptions to convey
# semantically useful errors.
except storage.Unavailable as e:
# Controllers raise Werkzeug HTTPExceptions for status >= 400.
raise InternalServerError('Please try again') from e # Chaining!
except storage.NoSuchResource as e:
raise NotFound('No such resource') from e
return {'thedata': data}, HTTPStatus.HTTP_200_OK, {}
Note that deserialization of the request body is a concern of the routes,
whereas the semantics of the request body are a concern of the controller.
If the request body is used, therefore, the controller should expect to receive
any URL paramters plus the whole request body as a collection (e.g. a dict
or MultiDict). See Routes for an example.
Testing controllers¶
Controller tests should simulate a wide range of request parameters. Any services used by the controller should be mocked using the built-in unittest.mock module.
Here is a simple example:
from unittest import TestCase, mock
from werkzeug.exceptions import NotFound
from ...services import storage
from .. import operation_a
class TestGettingSomething(TestCase):
"""Tests requests for a something."""
@mock.patch(f'{operation_a.__name__}.storage.SomeService')
def test_get_a_nonexistant_something(self, mockSomeService):
"""The requested something does not exist."""
mock_service = mock.MagicMock()
mock_service.get_a_thing.side_effect = storage.NoSuchResource
mockSomeService.current_session.return_value = mock_service
with self.assertRaises(NotFound):
operation_a.retrieve_something('foo')
Routes¶
Routes modules implement Flask blueprints that define the external HTTP endpoints for the service. Routes for external APIs, internal (service to service) APIs, and external UIs should be defined in separate blueprints each in its own module (even if they invoke the same controllers).
The routes module is where:
Authorization rules are defined; see
arxiv.users.Serialization/deserialization and template rendering are handled.
Routes utilize the internal calling APIs provided by the controller modules.
In order to facilitate unit tests, significant business logic should reside in the controller modules, and not in the routes modules.
For example:
from flask import Blueprint, render_template, Response, make_response
from foo.controllers import operation_a
# Generally, you will want to avoid URL prefixes for the blueprint.
blueprint = Blueprint('application', __name__, url_prefix='')
@blueprint.route('/something/<string:document_id>', methods=['GET'])
def something(document_id: str) -> Response:
"""
Handle requests to GET a something.
Parameters
----------
document_id : str
Identifier of the something.
Returns
-------
:class:`flask.Response`
Resource with an HTML representation of the something.
"""
data, status_code, headers = operation_a.retrieve_something(document_id)
response: Response = make_response(render_template('some.html', **data))
response.headers.extend(headers)
response.status_code = status_code
return response
When implementing blueprints, keep in mind that deserialization is in-scope for a route function, but the semantics of the payload generally is not. In other words, the route function should deserialize the request body (if accepted), but not attempt to interpet its contents–that’s up to the controller. Here’s an example of a route and a controller working together to interpret a request:
# routes.py
from typing import Dict, Optional
from flask import request, Response, jsonify, make_response
@blueprint.route('/{foo}', methods=['POST'])
def make_something(foo: str) -> Response:
"""
Handle request to create a something.
Parameters
----------
foo : str
The something to create.
Returns
-------
:class:`flask.Response`
"""
# get_json() will return None if the request content type is not JSON.
payload: Optional[Dict[str, Any]] = request.get_json()
data, code, headers = controllers.make_a_foo(foo, payload)
response: Response = make_response(jsonify(data))
response.headers.extend(headers)
response.status_code = code
return response
# controllers.py
from typing import Tuple, Dict, Any, Optional
from http import HTTPStatus
from werzeug.exceptions import BadRequest
Response = Tuple[Dict[str, Any], HTTPStatus, Dict[str, str]]
def make_a_foo(foo: str, payload: Optional[Dict[str, Any]]) -> Response:
"""
Make a new foo.
Parameters
----------
foo : str
The foo to make.
payload : dict or None
The deserialized request payload. Will be ``None`` if no data could
be coherently obtained from the request body.
"""
if payload is None:
raise BadRequest('Missing request payload')
...
Configuration¶
A configuration module (config.py) should define any relevant Flask
configuration parameters, plus any additional parameters for database
connections, logging, etc. See http://flask.pocoo.org/docs/1.0/config/.
Environment variables relevant to the application should be loaded in the
configuration module using os.environ. For common configuration parameters
(e.g. DATABASE_URI), a service-specific prefix may be used to avoid
collisions (e.g. FOOSERVICE_DATABASE_URI).
# config.py
# Default to an in-memory sqlite db for dev/testing.
DATABASE_URI = os.environ.get('FOOSERVICE_DATABASE_URI', 'sqlite:///')
For an extensive example, see https://github.com/arXiv/arxiv-submission-ui/blob/develop/submit/config.py.
Application factory¶
We use the application factory pattern for all of
our Flask apps. An app factory is just a function that returns a Flask app.
They live in application/factory.py.
Factory functions are responsible for:
Instantiating the Flask app;
Attaching blueprints;
Configuring the app;
Adding extensions and middlewares;
Attaching error handlers;
Performing start-up checks for dependencies/upstream services.
For a good example of an app factory that does all of these things, check out https://github.com/arXiv/arxiv-submission-ui/blob/develop/submit/factory.py#L1.
Health check/status endpoint¶
Status endpoints are used to:
Let other services know that the service is up and working normally.
Let the service orchestration system know that the service has started successfully and can start handling requests.
Let the service orchestration system know that the service is still running and functioning normally.
The endpoint should:
Accept
GETrequests.Usually be located at
/status.Return a response relatively quickly, especially if other services depend on it. But this need not be as responsive as a user-facing endpoint.
Do as much as possible to exercise upstream dependencies or other components that may be prone to failures. For example, the controller that handles the status request might call the status endpoints of upstream services. Or, even better, make a request to an upstream service that actually exercises that service’s functionality.
Return
200 OKif the service is operating normally.Return
503 Service Unavailableif the service is not operating normally.Return a small JSON payload that conveys additional semantics about the state of the service.
The body of the return could include the status of any upstream service upon which it depends:
{
"database": true,
"notifications": false
}
Templates¶
Flask uses the Jinja2 templating framework to render HTML pages.
Templates live in [repo root]/[app root]/templates/[app name].
Each service that provides an external user interface should provide a base
template (e.g. templates/[app name]/base.html) that is extended by
view-specific templates. This should almost always extend the base.html
template in the Base templates.
For examples, see the https://github.com/arXiv/arxiv-submission-ui/tree/develop/submit/templates/submit.
The location of application templates is set when the Flask application is instantiated in the application factory.
Base templates¶
The arxiv-base-ui package provides base templates and static assets (including stylesheets) for arXiv applications.
The base UI package provides a Base object that attaches base templates
and static assets to the application. It should be imported in the application
factory, and instantiated before registering service blueprints.
from foo.routes import external_api, ui
from baseui import BaseUI
def create_web_app() -> Flask:
"""Initialize and configure the foo application."""
app = Flask('foo')
app.config.from_pyfile('config.py')
Base(app) # Gives us access to the base UI templates and resources.
app.register_blueprint(external_api.blueprint)
app.register_blueprint(ui.blueprint)
return app
Static assets¶
Static files live in [repo root]/[app root]/static. In general, they should
be separated into subdirectories based on file type, e.g. css, js,
sass.
For examples, see: https://github.com/arXiv/arxiv-submission-ui/tree/develop/submit/static.
The location of application static files is set when the Flask application is instantiated in the application factory.
In production, static files will be served via S3.
Schema¶
OpenAPI¶
Applications that expose an API must have an OpenAPI <https://github.com/OAI/OpenAPI-Specification> >= v3.0.2 specification that describes the behavior of the API. This is used internally for testing and documentation, and is also used to generate human-friendly documentation for external developers when we expose the API via the gateway.
For an example, see https://github.com/arXiv/arxiv-search/blob/master/schema/search.yaml.
The OpenAPI schema should live at schema/[schema name].yaml.
The OpenAPI schema should link to JSON Schema for returns, for example: https://github.com/arXiv/arxiv-search/blob/740b5ff0a59b6f239f6ab545198e95e9f9a8ba96/schema/search.yaml#L439-L444.
JSON Schema¶
In addition, any resource exposed via the API should have a corresponding
JSON Schema document. These live in
schema/resources/.
Here is an example: https://github.com/arXiv/arxiv-search/blob/master/schema/resources/DocumentMetadata.json.
We use the jsonschema package in app tests, to verify that the app returns well-formed data.
We also uses these for developing service integration modules in other apps that depend on backend APIs.
WSGI module¶
The primary entrypoint for a service in production is a PEP 3333 Web Server Gateway
Interface (WSGI) application provided by wsgi.py in the root of the
project. It relies on the application factory to
provide a callable application object that handles requests.
Note
In Apache…
Variables set with the SetEnv directive in
Apache are passed in each request; the application object is therefore
responsible for setting those variables in the application runtime
environment to be picked up by the configuration module.
Here’s an example:
import os
from typing import Callable, Iterable
from flask import Flask
from foo.factory import create_web_app
__flask_app__: Flask = create_web_app()
def application(environ: dict, start_response: Callable) -> Iterable:
"""WSGI integration for Flask application."""
for key, value in environ.items():
if key == 'SERVER_NAME':
continue
if isinstance(value, str):
os.environ[key] = value
if key in __flask_app__.config:
__flask_app__.config[key] = value
return __flask_app__(environ, start_response)
Application server config¶
A successfully implemented Flask application provides a threadsafe mechanism for handling individual HTTP requests via WSGI. In order to handle many concurrent requests in production, however, we require an application server that can dispatch requests to the Flask application.
Services deployed in the classic architecture will sit behind Apache, and be served via the mod_wsgi module. Apache is responsible for managing concurrent processes and/or threads to accommodate client requests.
Services deployed in the NG cluster in AWS will run behind NGINX <https://nginx.org/en/>, which does not natively support WSGI. In this scenario, we use NGINX as a reverse proxy for uWSGI, which acts as the application server.
The entrypoint for the service in production will look something like:
uwsgi --ini uwsgi.ini
And the configuration file (uwsgi.ini) looks like:
[uwsgi]
http-socket = :8000
chdir = /opt/arxiv/
wsgi-file = wsgi.py
callable = application
master = true
harakiri = 30
manage-script-name = true
processes = 8
queue = 0
threads = 1
single-interpreter = true
mount = $(APPLICATION_ROOT)=wsgi.py
logformat = "%(addr) %(addr) - %(user_id)|%(session_id) [%(rtime)] [%(uagent)] \"%(method) %(uri) %(proto)\" %(status) %(size) %(micros) %(ttfb)"
buffer-size = 65535
wsgi-disable-file-wrapper = true
Note mount = $(APPLICATION_ROOT)=wsgi.py; this allows us to deploy the
app at an arbitrary path.
Docker images¶
The production runtime for the service is defined in a Dockerfile in the root of the
repository. Since many repositories will provide multiple processes (e.g.
web and worker processes), Dockerfiles should be named with a descriptive
affix that corresponds to the name of the target Docker image. For example,
the Dockerfile for the worker process in the foo service might be named
Dockerfile-worker, which is used to generate the image
arxiv/foo-worker.
For an example, see https://github.com/arXiv/arxiv-submission-ui/blob/develop/Dockerfile.
In most cases, arXiv-NG Docker images should extend the base arXiv Docker
image, arxiv/base.
Built images are pushed to https://hub.docker.com/u/arxiv.
Worker pattern¶
A service may use an asynchronous worker pattern to implement long-running processes that should take place outside of a request context. This should be implemented using Celery.
Overview¶
The following components are required to implement the async worker in a service:
Configure the worker app in the central service config module.
Extend the Flask application factory to initialize the worker app.
Create a worker entrypoint module to run the worker.
application/
├── config.py # Service configuration module.
├── factory.py # Application factory module.
├── tasks.py # Task module.
├── worker.py # Worker entrypoint module.
.
Celery Configuration¶
Celery configuration parameters should be contained within the main
application config module. They should be
named using the CELERY_ prefix.
See the Celery docs <http://docs.celeryproject.org/en/latest/userguide/configuration.html> for details on configuration variables.
Here is an example of Celery configuration parameters in an app:
# --- CELERY CONFIGURATION
CELERY_REDIS_ENDPOINT = environ.get('REDIS_ENDPOINT', 'localhost:6379')
"""Hostname and port of the Redis used for task queueing and result storage."""
CELERY_BROKER_URL = "redis://%s/0" % CELERY_REDIS_ENDPOINT
CELERY_RESULT_BACKEND = "redis://%s/0" % CELERY_REDIS_ENDPOINT
CELERY_QUEUE_NAME_PREFIX = 'fulltext-'
CELERY_PREFETCH_MULTIPLIER = 1
"""
Prevent the worker from taking more than one task at a time.
In general we want to treat our workers as ephemeral. Even though Celery itself
is pretty solid runtime, we may lose the underlying machine with little or no
warning. The less state held by the workers the better.
"""
CELERY_TASK_ACKS_LATE = True
"""
Do not acknowledge a task until it has been completed.
As described for :const:`.worker_prefetch_multiplier`, we assume that workers
will disappear without warning. This ensures that a task will can be executed
again if the worker crashes during execution.
"""
CELERY_TASK_DEFAULT_QUEUE = 'fulltext-worker'
"""
Name of the queue for plain text extraction tasks.
Using different queue names allows us to run many different queues on the same
underlying transport (e.g. Redis cluster).
"""
CELERY_RESULT_EXTENDED = True
"""Keep task metadata around in the result backend."""
Task module¶
The task module should define all of the asynchronous tasks that are supported by the worker, as well as a friendly API for working with asynchronous tasks.
Tasks can be defined as Python functions. See the Celery documentation for details.
def do_nothing() -> None:
pass
The task module should define a worker application factory that creates and configures a Celery app, and registers tasks. Here is an example:
def create_worker_app(app: Flask) -> Celery:
"""
Initialize the worker application.
Returns
-------
:class:`celery.Celery`
"""
result_backend = app.config['CELERY_RESULT_BACKEND']
broker = app.config['CELERY_BROKER_URL']
celery_app = Celery('someapp',
results=result_backend,
backend=result_backend,
result_backend=result_backend,
broker=broker)
celery_app.conf.queue_name_prefix = app.config['CELERY_QUEUE_NAME_PREFIX']
celery_app.conf.task_default_queue = app.config['CELERY_TASK_DEFAULT_QUEUE']
celery_app.conf.prefetch_multiplier = app.config['CELERY_PREFETCH_MULTIPLIER']
celery_app.conf.task_acks_late = app.config['CELERY_TASK_ACKS_LATE']
celery_app.conf.backend = result_backend
celery_app.conf.result_extended = app.config['CELERY_RESULT_EXTENDED']
celery_app.task(do_nothing, name='do_nothing')
return celery_app
def get_or_create_worker_app(app: Flask) -> Celery:
"""
Get the current worker app, or create one.
Uses the Flask application global to keep track of the worker app.
"""
g = get_application_global()
if not g:
return create_worker_app(app)
if 'worker' not in g:
g.worker = create_worker_app(app)
return g.worker
The task module can then expose an API for creating tasks and getting their disposition. Here is an example of a function to create an async task:
def create_task(identifier: str, id_type: str, owner: Optional[str] = None,
token: Optional[str] = None) -> str:
"""
Create a new extraction task.
Parameters
----------
identifier : str
Unique identifier for the paper being extracted. Usually an arXiv ID.
pdf_url : str
The full URL for the PDF from which text will be extracted.
id_type : str
Either 'arxiv' or 'submission'.
Returns
-------
str
The identifier for the created extraction task.
"""
logger.debug('Create extraction task with %s, %s', identifier, id_type)
version = get_version()
storage = store.Storage.current_session()
try:
_task_id = task_id(identifier, id_type, version)
# Create this ahead of time so that the API is immediately consistent,
# even if it takes a little while for the extraction task to start
# in the worker.
storage.store(Extraction(
identifier=identifier,
version=version,
started=datetime.now(UTC),
bucket=id_type,
owner=owner,
task_id=_task_id,
status=Extraction.Status.IN_PROGRESS,
))
# Dispatch the extraction task.
celery_app = get_or_create_worker_app(current_app)
celery_app.send_task('extract',
(identifier, id_type, version),
{'token': token},
task_id=_task_id)
logger.info('extract: started processing as %s', _task_id)
except Exception as e:
logger.debug(e)
raise TaskCreationFailed('Failed to create task: %s', e) from e
return _task_id
And here is an example of a function used to check the status of a task. Note
that it returns a domain object of type Extraction.
def get_task(identifier: str, id_type: str, version: str) -> Extraction:
"""
Get the status of an extraction task.
Parameters
----------
identifier : str
Unique identifier for the paper being extracted. Usually an arXiv ID.
id_type : str
Either 'arxiv' or 'submission'.
version : str
Extractor version.
Returns
-------
:class:`Extraction`
"""
_task_id = task_id(identifier, id_type, version)
result = AsyncResult(_task_id, task_name='extract')
exception: Optional[str] = None
owner: Optional[str] = None
if result.status == 'PENDING':
raise NoSuchTask('No such task')
elif result.status in ['SENT', 'STARTED', 'RETRY']:
_status = Extraction.Status.IN_PROGRESS
elif result.status == 'FAILURE':
_status = Extraction.Status.FAILED
exception = str(result.result)
elif result.status == 'SUCCESS':
_status = Extraction.Status.SUCCEEDED
owner = str(result.result['owner'])
else:
raise RuntimeError(f'Unexpected state: {result.status}')
return Extraction(
identifier=identifier,
bucket=id_type,
task_id=_task_id,
version=version,
status=_status,
exception=exception,
owner=owner
)
Note that if a result backend is enabled, it can be helpful to explicitly mark a task as started. Otherwise, it will be difficult to differentiate the case that a task is pending from the case that a task simply does not exist. Here is an example of how one can do this in the task module using Celery signals:
from celery.signals import after_task_publish
@after_task_publish.connect
def update_sent_state(sender: Optional[str] = None,
headers: Optional[Dict[str, str]] = None,
body: Any = None, **kwargs: Any) -> None:
"""Set state to SENT, so that we can tell whether a task exists."""
celery_app = get_or_create_worker_app(current_app)
task = celery_app.tasks.get(sender)
backend = task.backend if task else celery_app.backend
if headers is not None:
backend.store_result(headers['id'], None, "SENT")
It can also be helpful to define an availability check that can be used when evaluating the readiness of the web service as a whole. For example:
# In the tasks.py module...
def is_available(await_result: bool = False) -> bool:
"""Verify that we can start extractions."""
logger.debug('check connection to task queue')
try:
celery_app = get_or_create_worker_app(current_app)
task = celery_app.send_task('do_nothing')
except Exception:
logger.debug('could not connect to task queue')
return False
logger.debug('connection to task queue ok')
if await_result:
try:
logger.debug('waiting for task result')
task.get() # Blocks until result is available.
except Exception as e:
logger.error('Encounted exception while awaiting result: %s', e)
return False
return True
...
# The service readiness controller:
def service_status() -> Response:
"""Handle a request for the status of this service."""
stat = {
'storage': store.Storage.current_session().is_available(),
'extractor': tasks.is_available(await_result=True)
}
if not all(stat.values()):
raise ServiceUnavailable(stat)
return stat, status.OK, {}
Service application factory¶
The application factory defined for the service should be extended to initialize the worker app using the factory function defined in the tasks module.
Note that the worker app is initialized via the app factory in both the web service process and in the worker process when deployed, but it may be necessary or desirable to initialize services differently depending on whether or not the app is running in one or the other of those contexts.
For example:
from . import tasks
def create_web_app(for_worker: bool = False) -> Flask:
"""Initialize an instance of the web application."""
app = Flask('fulltext')
app.config.from_pyfile('config.py')
Base(app)
Auth(app)
app.register_blueprint(routes.blueprint)
store.Storage.current_session().init_app(app)
middleware = [auth.middleware.AuthMiddleware]
if app.config['VAULT_ENABLED']:
middleware.insert(0, vault.middleware.VaultMiddleware)
wrap(app, middleware)
if app.config['VAULT_ENABLED']:
app.middlewares['VaultMiddleware'].update_secrets({})
if app.config['WAIT_FOR_SERVICES']:
time.sleep(app.config['WAIT_ON_STARTUP'])
with app.app_context():
wait_for(store.Storage.current_session())
if for_worker:
wait_for(extractor.do_extraction)
else:
wait_for(extract, await_result=True) # type: ignore
logger.info('All upstream services are available; ready to start')
register_error_handlers(app)
app.celery_app = tasks.get_or_create_worker_app(app)
return app
Worker entrypoint¶
The worker entrypoint module is the starting-point for execution of the worker process. It should instantiate a Flask app, the Celery worker app, and register any additional signal callbacks e.g. that should be executed when a worker process starts.
Here is an example, including pulling a Docker image that is used by the
worker and obtaining secrets from Vault using arxiv.vault.
"""Initialize the Celery application."""
import json
from typing import Any, Optional
from celery.signals import task_prerun, celeryd_init, worker_init
import docker
from docker.errors import ImageNotFound, APIError
from arxiv.base import logging
from arxiv.vault.manager import ConfigManager
from someapp.factory import create_web_app
from someapp.tasks import create_worker_app
logger = logging.getLogger(__name__)
app = create_web_app(for_worker=True)
app.app_context().push()
celery_app = create_worker_app(app)
__secrets__: Optional[ConfigManager] = None
if app.config['VAULT_ENABLED']:
__secrets__ = app.middlewares['VaultMiddleware'].secrets
@celeryd_init.connect # Runs in the worker right when the daemon starts.
def get_secrets(*args: Any, **kwargs: Any) -> None:
"""Collect any required secrets from Vault."""
if not app.config['VAULT_ENABLED']:
print('Vault not enabled; skipping')
return
for key, value in __secrets__.yield_secrets(): # type: ignore
app.config[key] = value
@celeryd_init.connect
def pull_image(*args: Any, **kwargs: Any) -> None:
"""Make the dind host pull the fulltext extractor image."""
client = docker.DockerClient(app.config['DOCKER_HOST'])
image_name = app.config['EXTRACTOR_IMAGE']
image_tag = app.config['EXTRACTOR_VERSION']
logger.info('Pulling %s', f'{image_name}:{image_tag}')
for line in client.images.pull(f'{image_name}:{image_tag}', stream=True):
print(json.dumps(line, indent=4))
logger.debug(json.dumps(line, indent=4))
logger.info('Finished pulling %s', f'{image_name}:{image_tag}')
@task_prerun.connect # Runs in the worker before start a task.
def verify_secrets_up_to_date(*args: Any, **kwargs: Any) -> None:
"""Verify that any required secrets from Vault are up to date."""
logger.debug('Veryifying that secrets are up to date')
if not app.config['VAULT_ENABLED']:
print('Vault not enabled; skipping')
return
for key, value in __secrets__.yield_secrets(): # type: ignore
app.config[key] = value