Architectural overview¶
Context¶
The arXiv search system supports queries about arXiv papers both from human users and from API clients (via the arXiv API gateway). Most readers arrive at the search interface via a small search bar in the running header of arxiv.org pages, or by clicking on the name of an author on the abstract page or other listings.
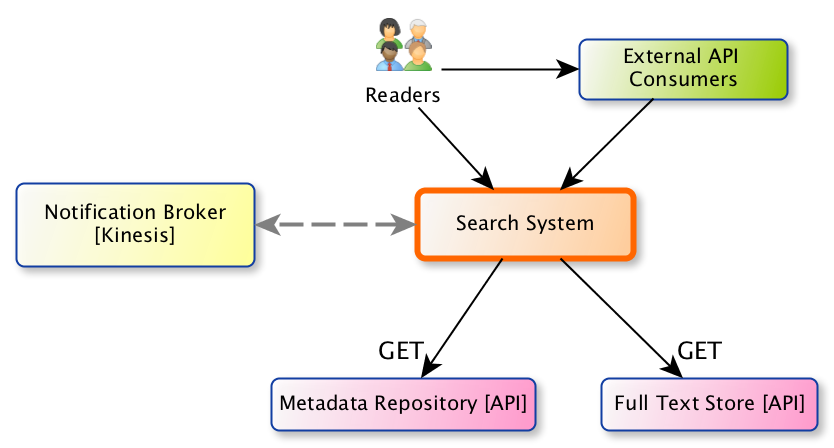
System context for arXiv search.
The search system draws content from the core metadata repository (currently
the classic arXiv application, via the docmeta endpoint), and (future)
from the fulltext extraction service.
Notifications about new content are disseminated by the publication system via a Kinesis stream. When metadata and/or the full text content (future) is available, the search system retrieves the relevant metadata and content from the metadata store and plain text store (future), respectively, and updates the search index.
In the future, the search system may be used to support other discovery tools and APIs, including the RSS feeds.
Containers¶
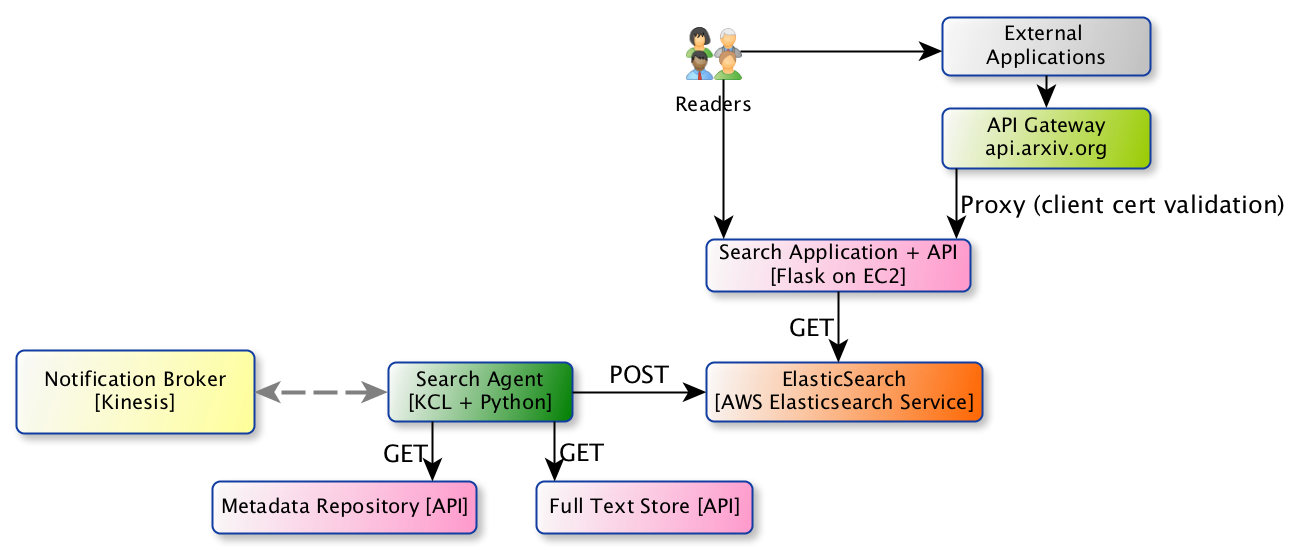
Container view of arXiv search.
The core of the search system is an ElasticSearch cluster, provided by the AWS Elasticsearch Service.
The search application, implemented in Python/Flask, provides both the
user-facing interfaces as well as a REST API. These two sets of endpoints
(search.routes.ui and search.routes.api) are deployed as two
separate services.
The indexing agent application is responsible for coordinating updates to the ElasticSearch cluster. The agent subscribes to notifications about the availability of metadata and/or plain text (future) for new publications delivered by the Kinesis broker. The agent makes requests to the metadata repository and the plain text store (future), transforms those data into a search document, and sends that document to ES.
Components: Search UI service¶
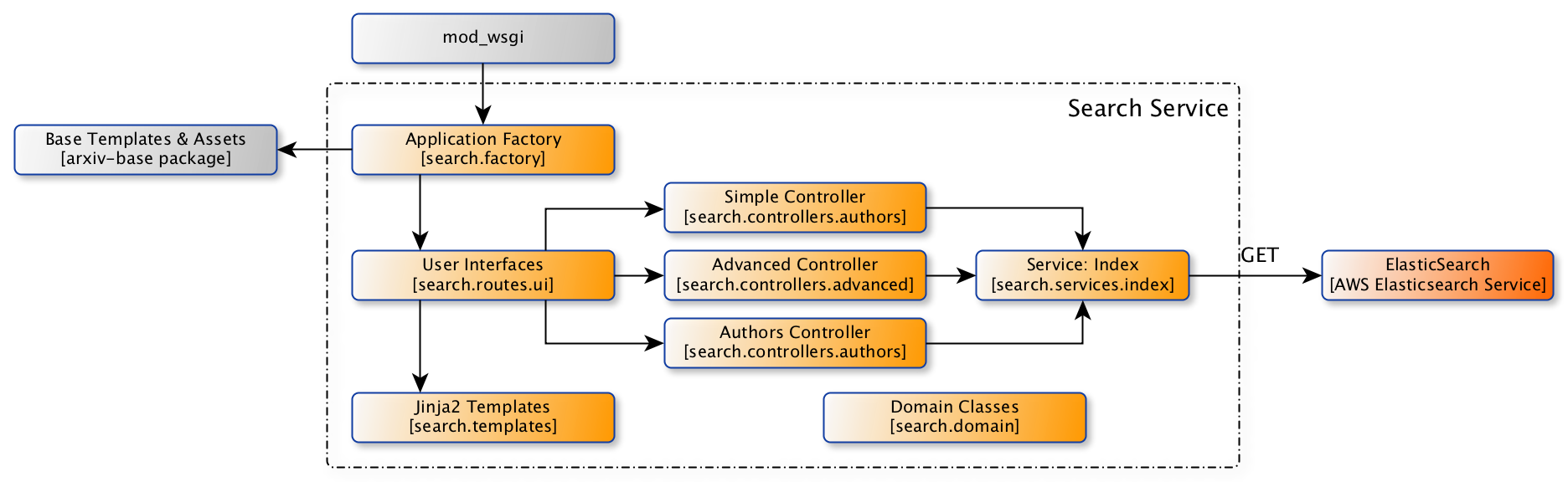
Components of the search service.
The search ui service is a Flask application that handles user/client requests to search arXiv papers.
The entry-point to the application is search.factory.create_ui_web_app().
That application factory function attaches templates and static files from
arxiv.base for use in search-specific templates,
and attaches the routing blueprint provided by search.routes.ui.
search.routes.ui routes parameters from incoming requests to the two
main search controllers:
These are implemented separately, rather than trying to accommodate all use-cases in one controller, because we expect user interface methods to change significantly as enhanced features are introduced. Each controller module implements its own classes for form handling and validation.
Components: Indexing agent¶
Notifications about new document metadata are handled by search.agent,
implemented using arxiv.base.agent. This class coordinates retrieval of
metadata from the docmeta endpoint (classic), transforms those content
into a search document using search.process.transform, and updates
ElasticSearch using search.services.index.