Submission & moderation subsystem architecture¶
Overview¶
The submission and moderation subsystem provides:
Accession of submission of e-print content and metadata via multiple interfaces, including interfaces provided by trusted third-party platforms;
Quality assurance tools and workflows to screen submissions (moderation);
An extensible system for automating parts of the moderation process;
An event-based log of all submission and moderation activity related associated with a paper.
In short, the submission and moderation subsystem is responsible for all submission-related activities up to (but not including) announcement.
- Submission subsystem
Refers to the collection of services/applications, data stores, and other components involved in the accession and moderation of new arXiv papers.
- Submission
Refers to a collection of descriptive and operational metadata, including a reference to a content object (e.g. a TeX source package, PDF, etc), that has been accessioned for possible announcement in arXiv.
Typical workflow¶
Submitters (and external services) generate new submissions, which are comprised of metadata and a content object (e.g. a tar/gzipped TeX source bundle, or a single PDF file). Prior to consideration by moderators, submissions may undergo several rounds of modification. Submitters may revise metadata and/or upload revised content. During this process a handful of different services may need to operate on the submission. For example, the content is compiled into an arXiv PDF; links are extracted for consideration by the submitter; etc.
Upon submission, the paper may be subject to a variety of processing and moderation activities. Automatic classification algorithms may be run, which require pre-processing steps (e.g. plain text extraction). Moderators may propose re-classification, act on input from classification algorithms, make comments, etc. Depending on moderator activity, additional input from the submitter and/or administrators may be necessary.
Key requirements¶
The subsystem must sensibly incorporate input from, and synchronize the activities of, a variety of human and non-human agents.
It must be possible for administrators to audit all changes to submission state in the subsystem (e.g. by submitters, moderators, automated processes, etc).
Administrators must be able to configure automated rules and processes.
The subsystem must support future development of potentially many alternative interfaces for submission and moderation, including interfaces developed and operated by trusted third-parties.
The subsystem must be able to support a high volume of activity. We currently process around 11,000 submissions per month (early 2018), and expect that to grow at least 10% per year.
The subsystem must make it easier to support future operational and policy changes around submission content, quality assurance, metadata, and other areas of concern.
Solution strategy¶
Major functional components of the classic submission system are decomposed into independent Utility services that are agnostic about the submissions themselves. This includes classification, overlap detection, compilation (TeX, PS), and upload/file management.
The core submission package provides the foundational logic of the submission system.
Defines the commands that are available in the submission system, and provide a Python API for executing those commands.
Provides integration with the Submission database.
A set of core submission interface services built on top of the core submission package provide UIs and APIs to support submission and moderation workflows.
The
agentprovides a framework for defining rules and conditional processes based on submission vents.
Context¶
This section describes the context for the submission system.
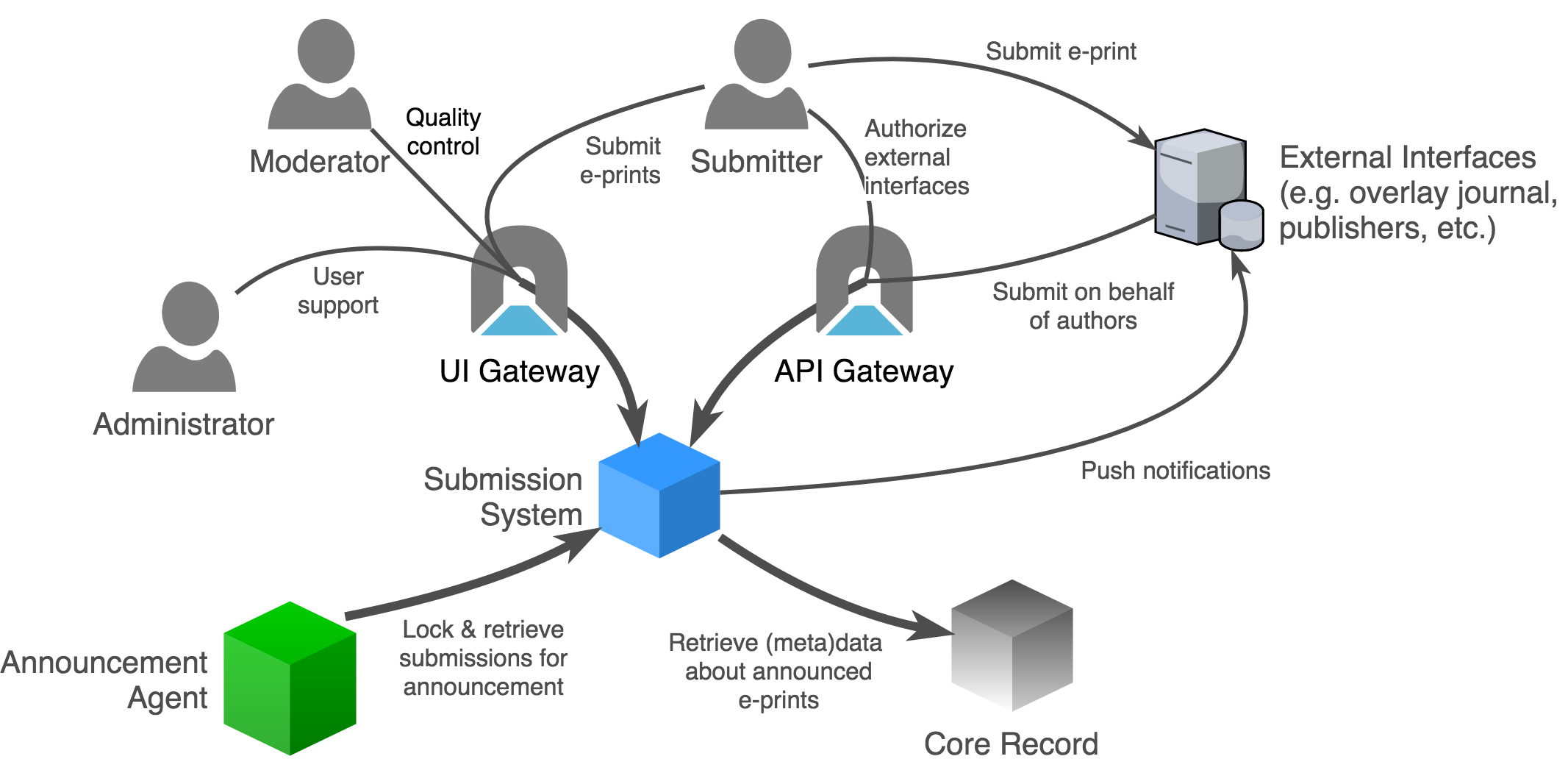
Fig. 1 System context for the arXiv submission system.¶
Authenticated users¶
Authenticated users submit new e-prints via a user interface. Users can view the status of their submissions, which may include feedback from administrators, and amend their submissions as necessary. They can also view a preview of their submission, and make amendments to the source files in their submission directly via the interface. Authors can supplement their announced and unannounced e-prints with links to external resources.
Moderators (authenticated users with a moderator role) screen and curate submissions through a moderation interface. They can generate comments, flags, proposals, and other annotations attached to submissions.
Administrators can audit and manage the submission platform, including the behavior of automated processes and policies, through an administrative interface.
API access¶
All API access passes through the arXiv API gateway.
The submission system provides a RESTful API for programmatic use. Clients may deposit submissions in bulk (e.g. conference proceedings), or on an individual basis on behalf of arXiv users. Authenticated arXiv users must explicitly authorize external API clients to deposit on their behalf. The submission system offers a web-hook notification service that pushes updates in submission state to authorized API clients.
A variety of backend services are exposed via the API gateway, including the file management system (to facilitate upload), compilation services, and classification services. Access to those services must be explicitly authorized by administrators.
Other arXiv services¶
During the daily announcement process, the Announcement agent retrieves information about announcement-ready submissions. The announcement agent moves submission content and metadata into the appropriate storage facilities, transitions the state of announced e-prints, and triggers downstream processes via the notification broker.
Some processes in the submission system require information about past arXiv papers. For example, classification, overlap detection, and other QA/QC services will keep themselves up to date by consuming metadata and content from announced e-prints in the canonical record.
Services & building blocks¶
The submission & moderation subsystem is comprised of the following parts:
The Submission database, which houses a detailed record of submission data events and projections.
A collection of submission, moderation, and administrative Core interface services. These include form-based user interfaces and RESTful APIs for external users/clients. Those interfaces interact with the core database via a shared library, which guarantees consistent mutations of submission data and application of business logic/rules.
A collection of Utility services, including services for compiling submissions to PDF, sanitizing uploads, and automated classification.
The Submission agent, which monitors submission events and runs backend processes (such as QA checks) based on a set of configurable rules.
A Web-hook notification service that disseminates submission-related events to authorized clients via HTTP requests.
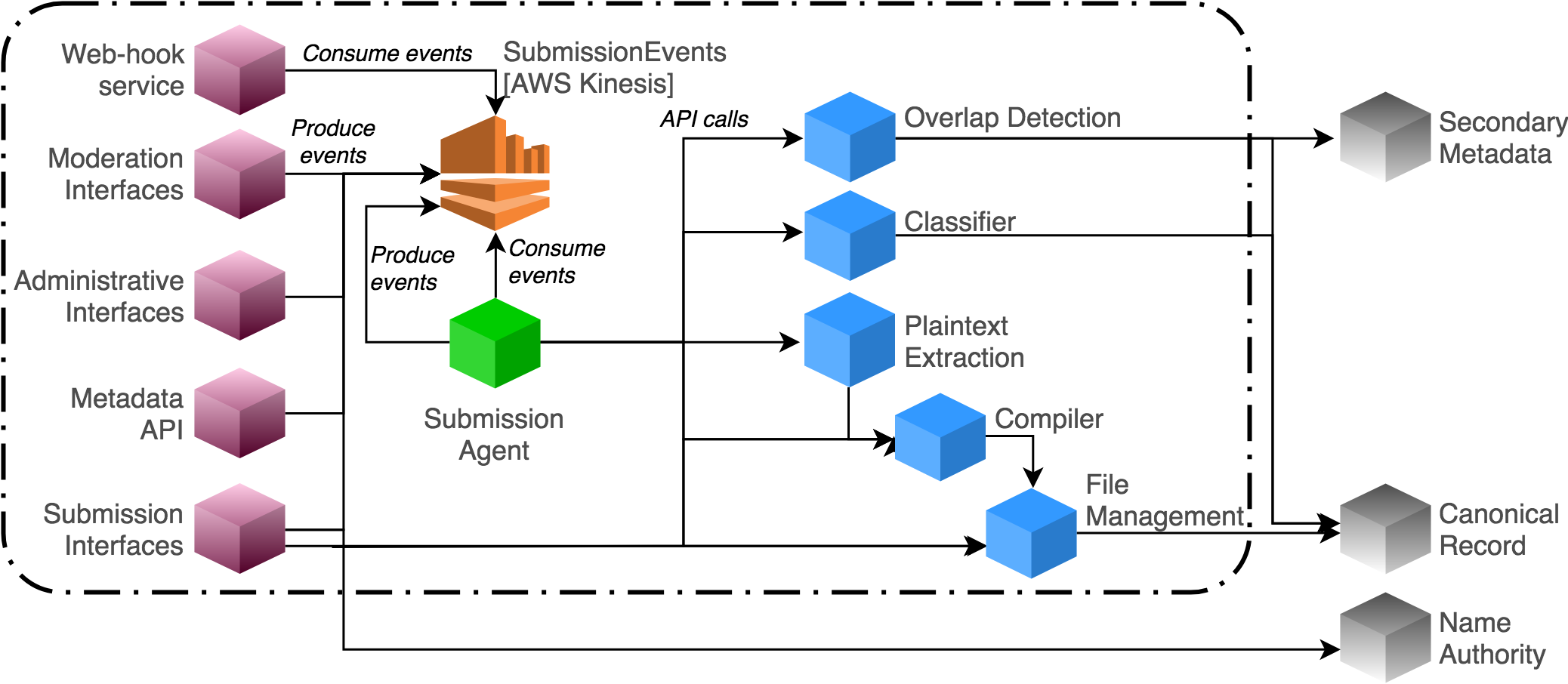
Fig. 2 Services in the arXiv submission subsystem.¶
Submission database¶
The submission database (currently MySQL) is responsible for the persistence of operational and core descriptive metadata about submissions. Operational metadata includes information related to arXiv workflows and processes. Core descriptive metadata are the core metadata fields required for arXiv submissions (e.g. title, authors, abstract). The primary source of truth for the state of each submission is a set of transformation events. Derivative representations (e.g. of submission objects) are also stored for querying and rapid access.
In early phases of the classic renewal process, this will be the classic MySQL database running in the CUL-IT datacenter. During the arXiv-NG project, submission data will be migrated to a standalone MariaDB or PostgresQL cluster in AWS RDS.
Submission core package¶
This package provides an event-based Python API for mutating submissions, and is the only mechanism for writing submission data to the Submission database. This package is used by both the Core interface services and the Submission agent.
Provides a set of commands (events) that canonicalize operations on submissions, and are used as the basis for composing rule-based processing tasks for quality control.
Provides service integration modules for working with utility services (e.g. Utility services)
Provides integration with a notification broker (Kinesis) for disseminating events to other parts of the system (e.g. Submission agent).
Detailed package documentation can be found in arxiv.submission.
Submission agent¶
The agent orchestrates backend processes based on rules triggered by
submission events.
The primary concerns of the agent are:
Orchestrating automated processes in support of submission and moderation.
Keeping track of what processes have been carried out on a submission, and the outcomes of those processes.
Providing a framework for defining conditions under which processes should be carried out.
Processes are carried out asynchronously, and may generate additional events which are emitted via the notification broker. Relies on a task queue (Redis) implemented using Celery.
Core interface services¶
These services provide the core submission, moderation, and administrative interfaces for the arXiv submission subsystem. Each of these services integrates with the Submission database to modify submission state, via the Submission core package.
These core interface services integrate with other services in the submission subsystem (e.g. File management service, Compilation service) via their HTTP APIs.
Submission UI¶
https://github.com/cul-it/arxiv-submission-ui
Provides form-based views that allow users to create and update submissions, and track the state of their submission through the moderation and announcement process. The interface supports metadata entry, source package upload, and integrates with the Compilation service to assist the submitter in preparing an announcement-ready submission package.
Uses the Submission core package to update submission state in the Submission database.
Submission API service¶
https://github.com/cul-it/arxiv-submission-core/tree/master/metadata
Provides a RESTful API for trusted clients to facilitate submission to arXiv via external/third-party user interfaces. Uses the Submission core package to update submission state in the Submission database.
This will replace the existing arXiv SWORDv1 API.
Moderation UI service¶
Supports moderator actions on submissions. Comprised of a client-side application (implemented in React) backed by a lightweight Flask service. Uses the Submission core package to update submission state in the Submission database.
Administrative UI service¶
The administrator interfaces provides visibility onto all parts of the submission service, including the state and event history of all submissions and submission annotations in the system. Administrators are able to configure automated policies and processes, intervene on submission content and metadata, and act on moderator proposals and comments.
Utility services¶
The following utility services support the submission and moderation workflow, providing a menu of functionality used by UI and API services to support accession and quality assurance.
File management service¶
https://github.com/cul-it/arxiv-filemanager
This service is responsible for ensuring the safety and suitability of files uploaded to the submission subsystem. The file management service accepts uploads, performs verification and sanitization, and makes the upload available for use by other services.
During on-premises deployment, the file management service is backed by an SFS volume provided by Cornell IT. Upon migration to the cloud, the file management service will be backed by an EFS volume.
Compilation service¶
https://github.com/cul-it/arxiv-converter
The build service compiles sanitized upload packages into PDF, PostScript, and other formats. This service encompasses the arXiv TeX tree. Compilation logs are also made available, for example to provide submitters feedback about compilation failures or warnings.
The compilation service is backed by an AWS S3 bucket.
Plain text extraction service¶
https://github.com/cul-it/arxiv-fulltext
Extracts plain text content from PDFs, for use by the for overlap detection and classification services. Makes both raw extracted text and normalized “PSV” tokenized text available to other services.
Overlap detection service¶
https://github.com/cul-it/arxiv-docsim
Operates on extracted plain text content and submission metadata to detect possibly duplicate submissions. Returns an array of announced e-prints with a high degree of overlap.
Classifier service¶
https://github.com/cul-it/arxiv-classifier
Operates on extracted plain text content and submission metadata to propose categories for submitted papers.
Notification service¶
Responsible for dispatching email notifications to submitters, moderators, in response to submission subsystem events. Provides UIs for end-user and administrator configuration.
Web-hook notification service¶
Provides mechanisms for API clients to register callbacks for submission events. Event consumer is implemented using the Kinesis Consumer Library and MultiLangDaemon [refs].
Example: integration with the auto-classifier¶
When a user finalizes their submission for announcement, we perform a variety of automated quality assurance checks to support the moderation process. This example illustrates how classification-related checks are implemented in the NG submission architecture.
The submitter finalizes their submission via the Submission UI. This may involve a POST request, including a field attesting to the submitter’s intent.
The submission UI generates a
FinalizeSubmissionevent usingarxiv.submission, persisting the event in the classic database and emitting the event on theSubmissionEventsKinesis stream.The Submission agent observes the
FinalizeSubmissionevent on theSubmissionEventsKinesis stream. This matches a rule that triggers theagent.process.RunAutoclassifierprocess.
Open problems/future development¶
The current implementation of the core submission package is a step toward an event-sourcing framework
for the submission system. One of the core concepts of event-sourcing is that
we are able to generate the current state of an object (in this case, a
submission) from all of the events that have occurred. Until we are able to
jettison legacy submission components, however, this will not be true: legacy
components will make direct mutations to rows in the legacy submission
database without generating events. Those changes must be inferred, which is
achieved in arxiv.submission.services.classic.interpolate.
A related problem is avoiding race conditions on the event stream. We must take care not to persist events that are inconsistent with the current state of the submission. In the long run, we will achieve this via an optimistic lock, e.g. by versioning the state of the submission and including the expected version with an event that we wish to persist. This will entail placing an event controller between event-generating applications and the event store, which will reject events for which there is a version mismatch. Since (as above) we are continuing to deal with legacy components that make direct writes to submission state, in the interim we will rely on the atomic transactions afforded by the legacy MySQL database, and ensure consistency by creating a short-lived shared lock on related submission rows while committing new events.
Finally, we ultimately want to avoid placing the responsibility for updating
the projected submission state on the applications that are generating events.
This is not possible in the short term for the reasons outlined above.
Currently, the event-generating application must read the submission state and
events from the legacy database, write both events and submission state to the
legacy database, and propagate events via the event stream. This is handled by
arxiv.submission.core.save(), and is implemented in a way that
preserves the ACIDity of the write.
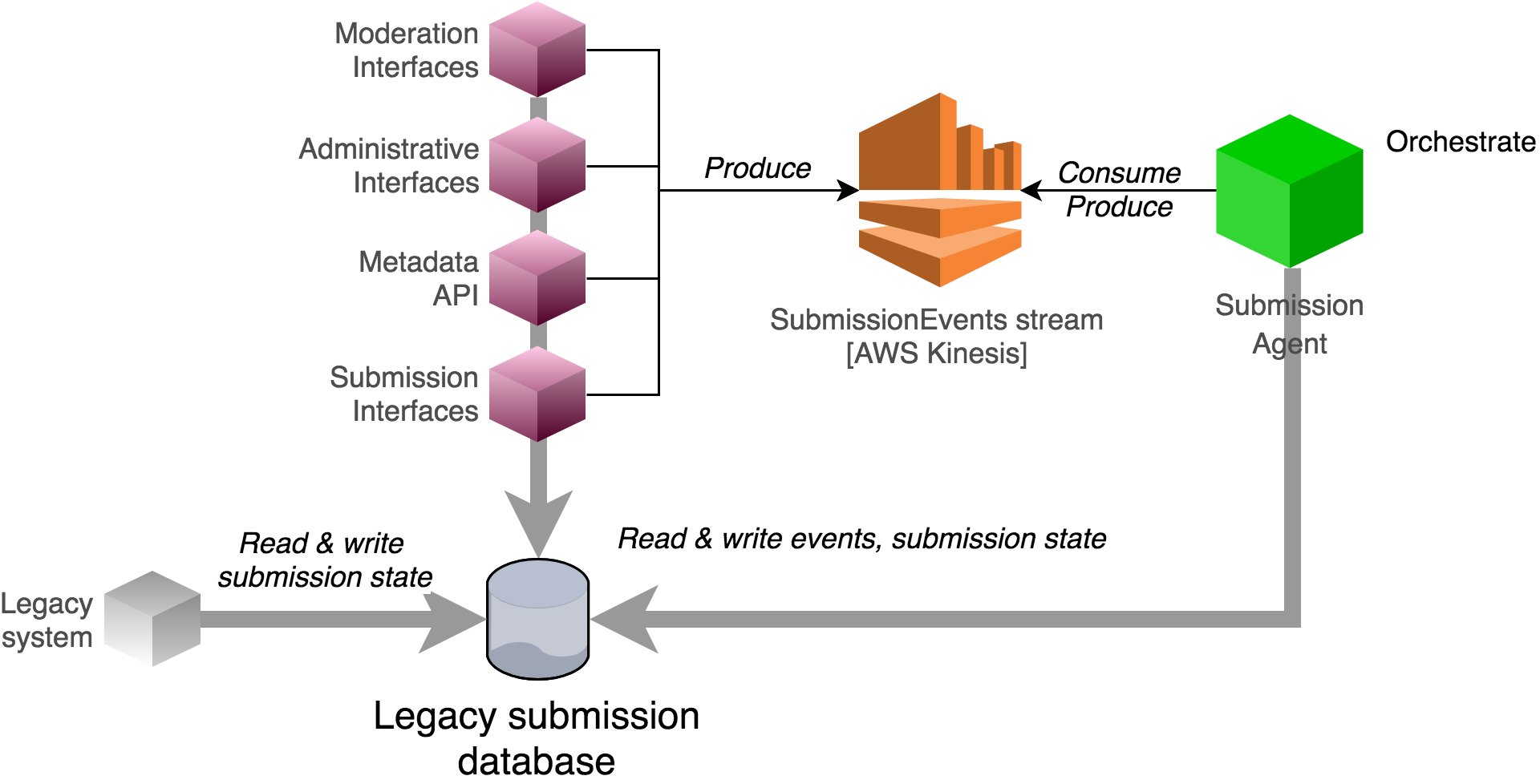
Fig. 3 Current implementation of submission events in the submission system, constrained by support for legacy integrations with the database. Applications that produce events must handle persistence (including consistency checks), updating the submission state, and propagating event notifications.¶
Once those constraints are lifted, however, applications generating events should only be reading the submission state from the/a submission database, and writing events to the event stream (e.g. by putting them to the event controller).
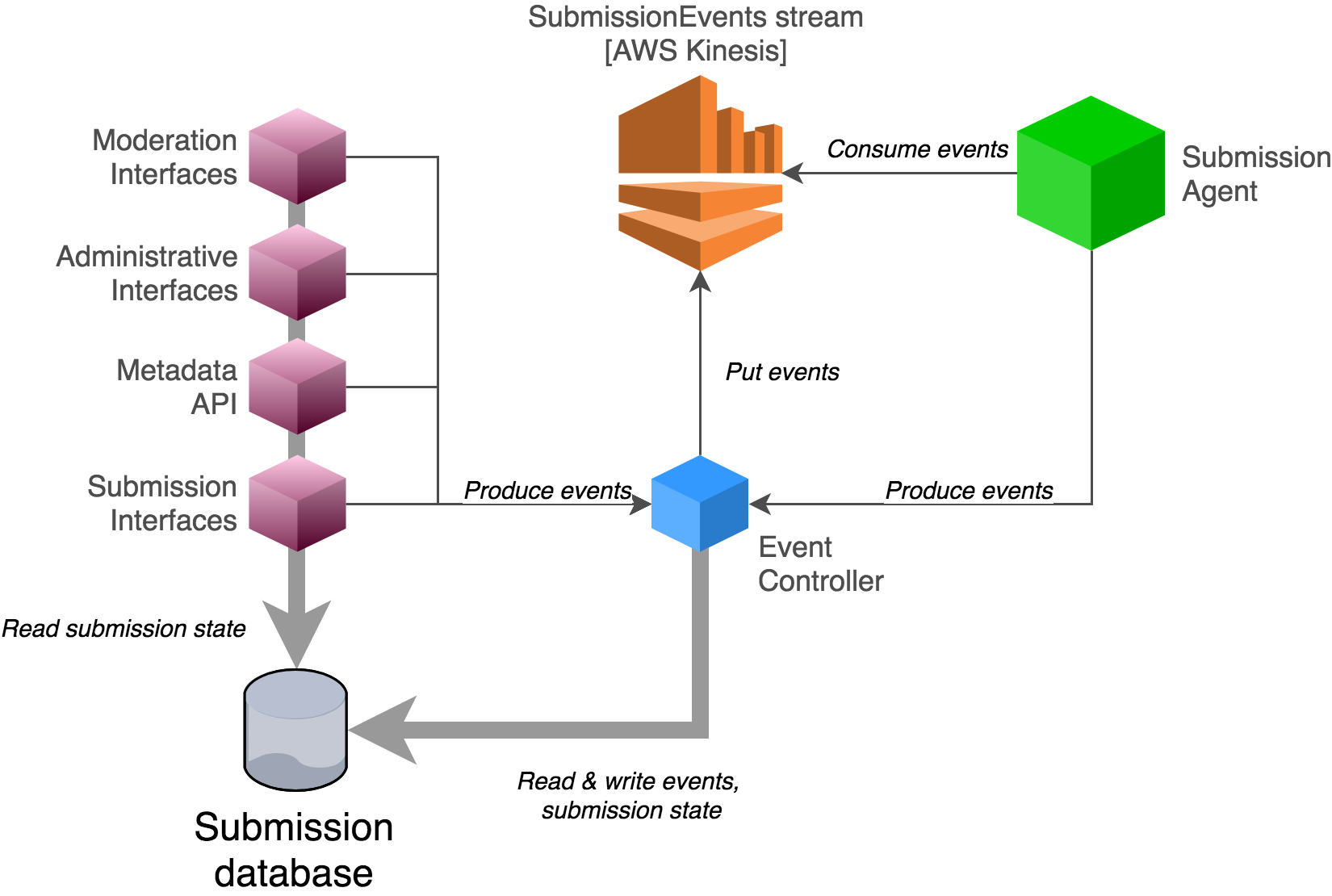
Fig. 4 Eventual implementation of submission events in the submission system, when legacy integrations with the database are no longer required. An event controller service assumes responsibility for ensuring the consistency of events, persisting/propagating the event stream, and updating the read database. All other applications use the database for reads only, and produce events via the event controller.¶