arXiv Classic¶
The classic (legacy) arXiv system is comprised of several main systems, including a collection of Perl CGI scripts and Perl/Catalyst modules, asynchronously executed announcement and notification programs, document source processing tools, and other systems.
These systems and their subsystems are (in theory) largely functionally separable, but they are implemented in such a way as to be deeply intertwined by shared abstractions that sometimes obscure business logic and hamper the development of new features. A major focus of NG will be disentangling those functional parts to facilitate more cost-effective and sustainable development.
Subsystems¶
The subsystem diagram is an attempt to describe the major components of the arXiv system, including development systems. In theory, each subsystem represents a set of components that can be deployed independently of the other subsystems in the system. In practice, this is not quite accurate.
For example, the automated publishing system and the announcement email alert system can be described as more-or-less separate systems, but in the current implementation of the system they are bound up together in the implementation of the daily announcement process.
An additional complication that is not represented here is that many of the system subsystems depend on a single package, arxiv-lib, which provides a significant share of the functionality and the main data abstractions in the system; thus the separability of those subsystems boils down to separation of business concerns in that underlying package.
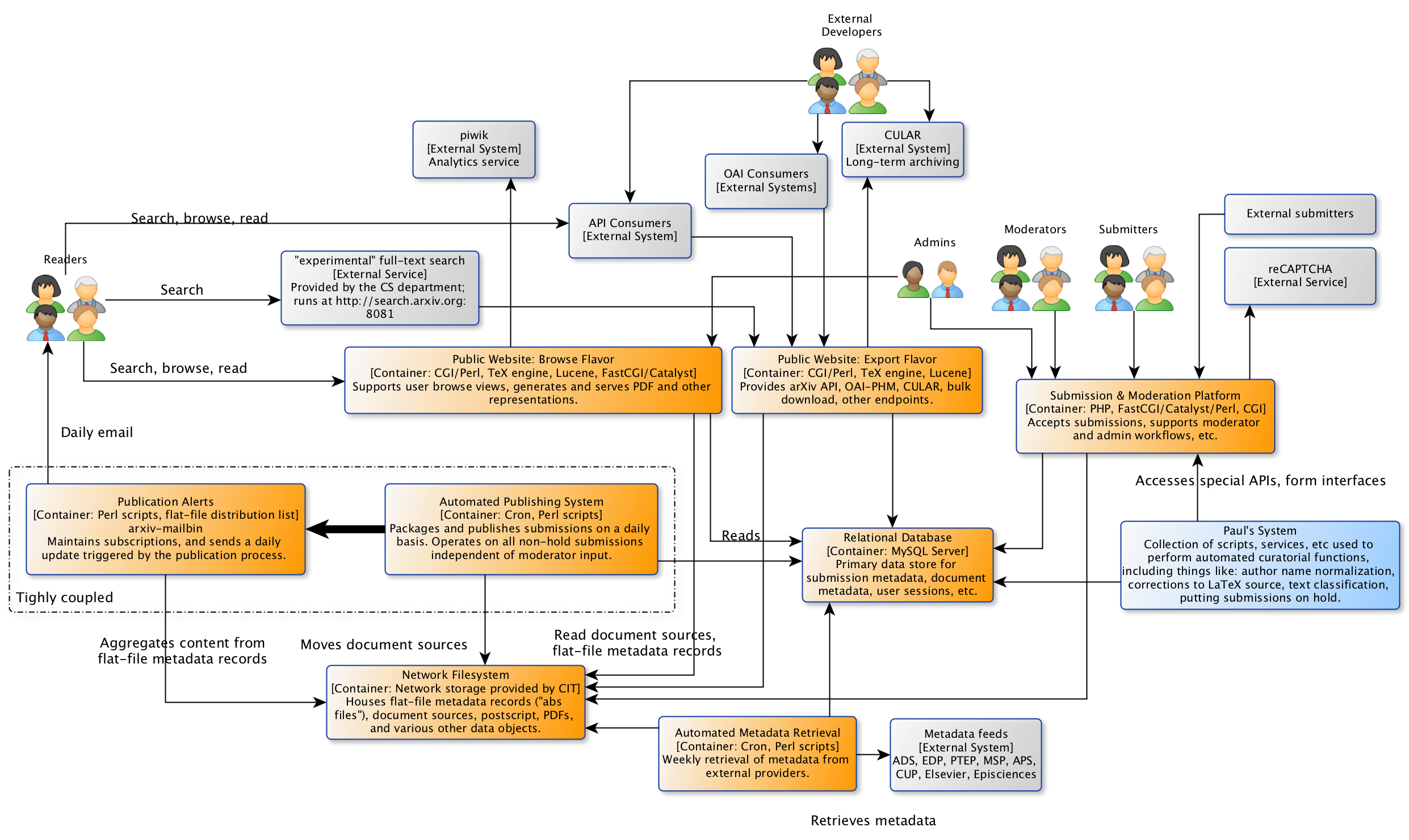
Fig. 2 subsystem diagram for arXiv classic.¶
Relational Database¶
The primary datastore for arXiv is a single relational database implemented in MySQL. That database is replicated across several MySQL servers, some of which service user-facing “web” nodes (the “browse flavor” of the public website) and the submission/moderation platform, and some of which service the “export” nodes (the “export flavor” of the public website).
Network Filesystem¶
All submission and announcement content is stored in a network filesystem provided by arxiv. State changes in submissions, including TeX compilation and Announcement, involve shuffling content objects around on this filesystem. The network filesystem supports the browse and export flavors of the public website, the submission and moderation platform, and the automated announcement and notification systems.
Submission & Moderation Platform¶
The submission and moderation platform provides a collection of form-driven views for submitters, moderators, and administrators. This system runs on the same web servers as the browse flavor of the public website. Components of the platform are implemented variously in PHP and Perl. Submission state, including moderation and administration flags, are stored in the relational database. User uploads are stored in the network filesystem, and submission processing activities involve modifying and shuffling content on the filesystem.
Components¶
The submission and moderation platform includes a PHP application called TAPIR, which provides user administration functionality, and a set of Perl/Catalyst controllers deployed as CGI scripts that provide submission, moderation, and administrative endpoints.
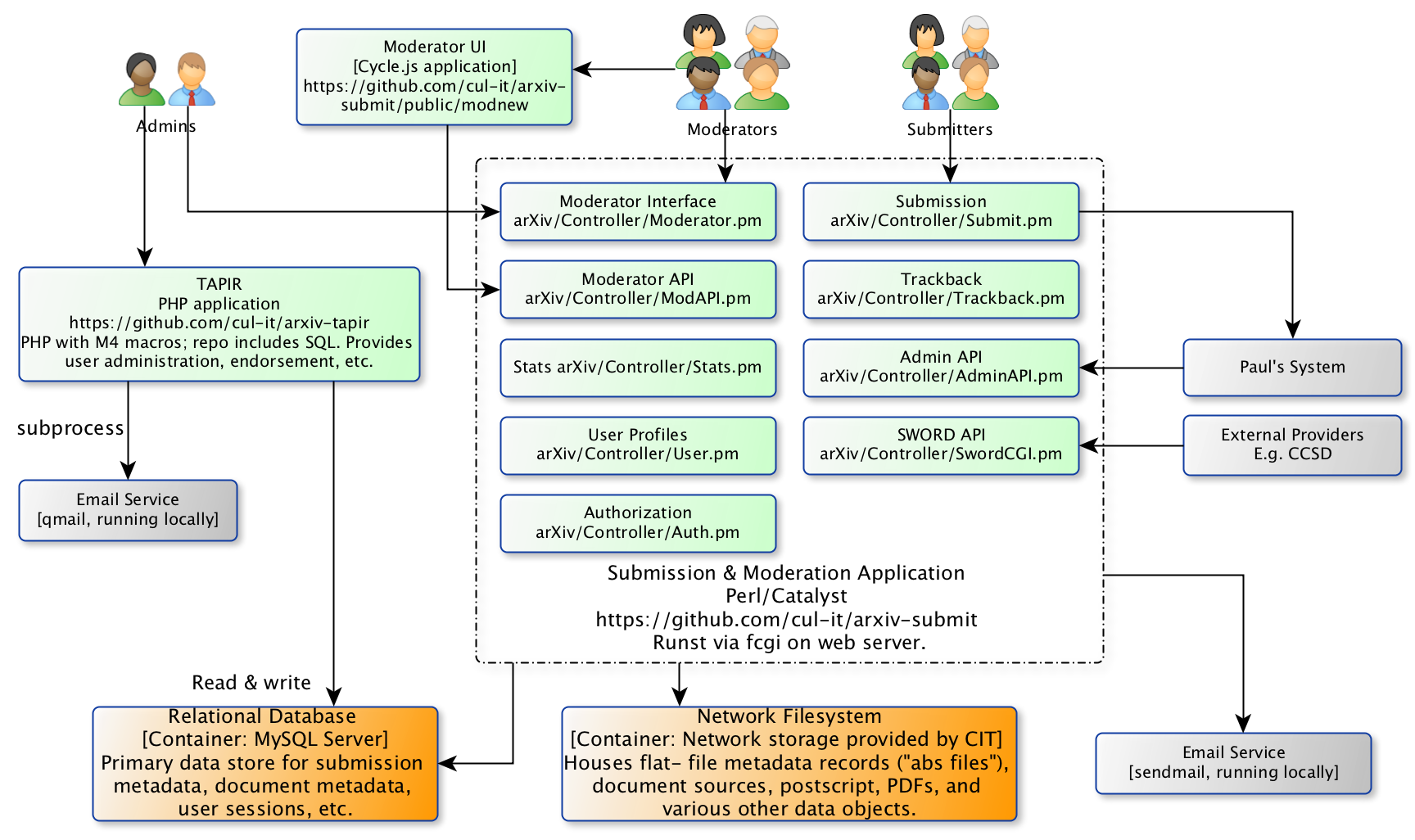
Fig. 3 Component diagram for the submission & moderation platform in arXiv classic.¶
Sitting below each of the Perl/Catalyst controllers is a fairly extensive set of shared abstractions provided by the arxiv-lib package . That library encapsulates database interactions, some filesystem operations, and a considerable amount of business logic.
Integrations with adjacent and external systems occur in a variety of places. The TAPIR application uses the local qmail service to send emails. Perl/Catalyst components largely rely on local sendmail for that purpose.
The submission system interacts via HTTP requests with a classifier service provided by Paul G., running on an external machine. Other processes controlled by Paul G. intervene on the submission database and uploads via a special- purpose admin API and through form-driven administration interfaces.
External content providers can submit announcements via a SWORD API.
Recently, moderators interact with a client-side application, the moderation UI, implemented in Cycle.js. The moderation UI relies on a server-side moderation API.
Public Website¶
Browse Flavor¶
This system services requests to arxiv.org, and is the primary public-facing aspect of the arXiv system. Readers can browse categories for new announcements, search for announcements, and access announcement content. Some of the views in this system rely on content stored in flat-file metadata records called “abs files” that are stored on the network filesystem.
Export Flavor¶
This system provides programmatic access to arXiv content. This includes the arXiv API, bulk export endpoint, log endpoint, an OAI-PMH endpoint, and others. It relies on both the relational database and the network filesystem.
Components¶
The browse and export flavors of the public website are comprised of collections of Perl controllers run via CGI. For the most part, each Perl CGI script is responsible for a single route provided by the web server. These scripts are provided by the arxiv-httpd package, which in turn relies heavily on arxiv-lib for database and filesystem abstractions and some business logic. The two flavors are implemented through selective definition of routes in the Apache configuration.
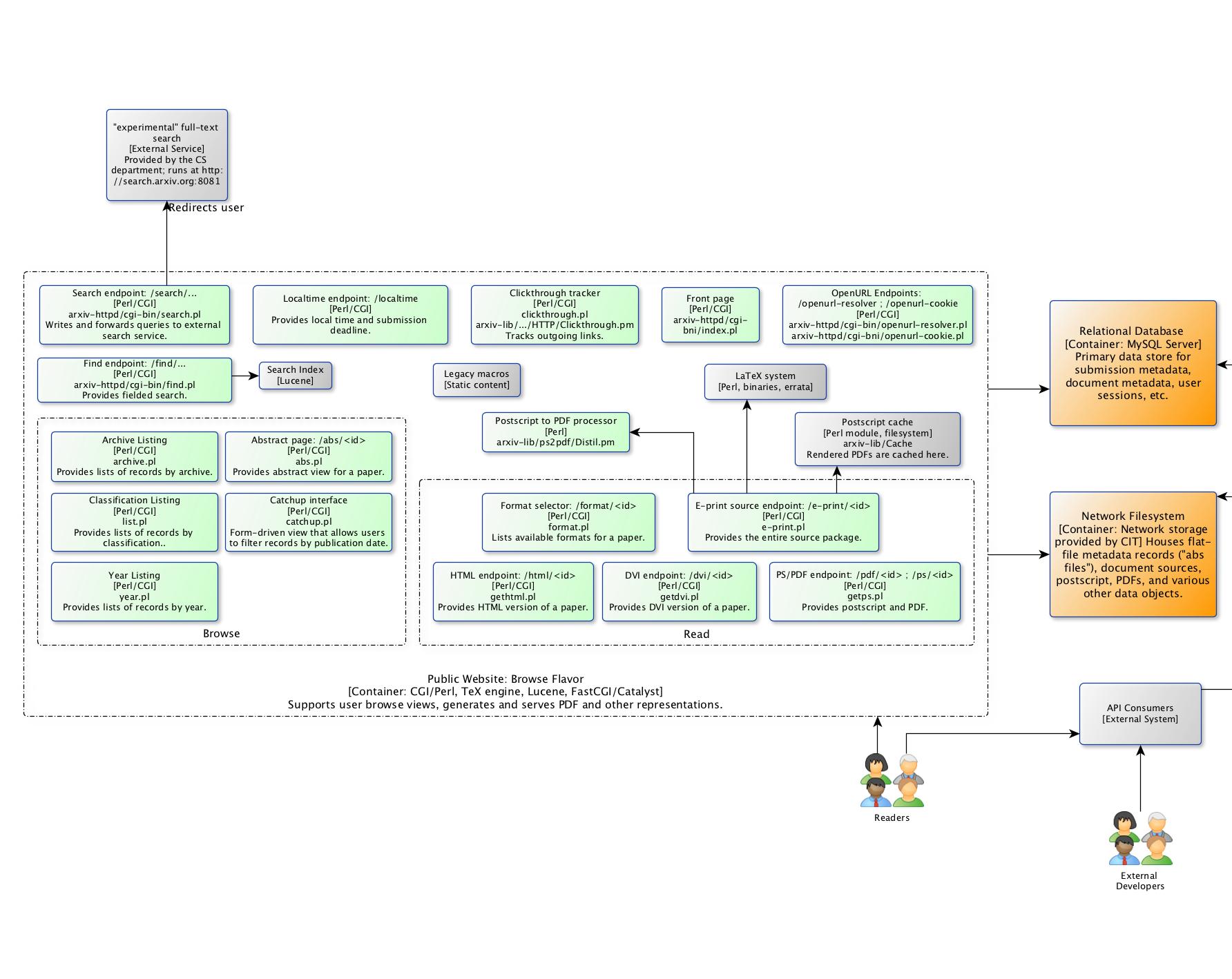
Fig. 4 Public website, browse flavor.¶
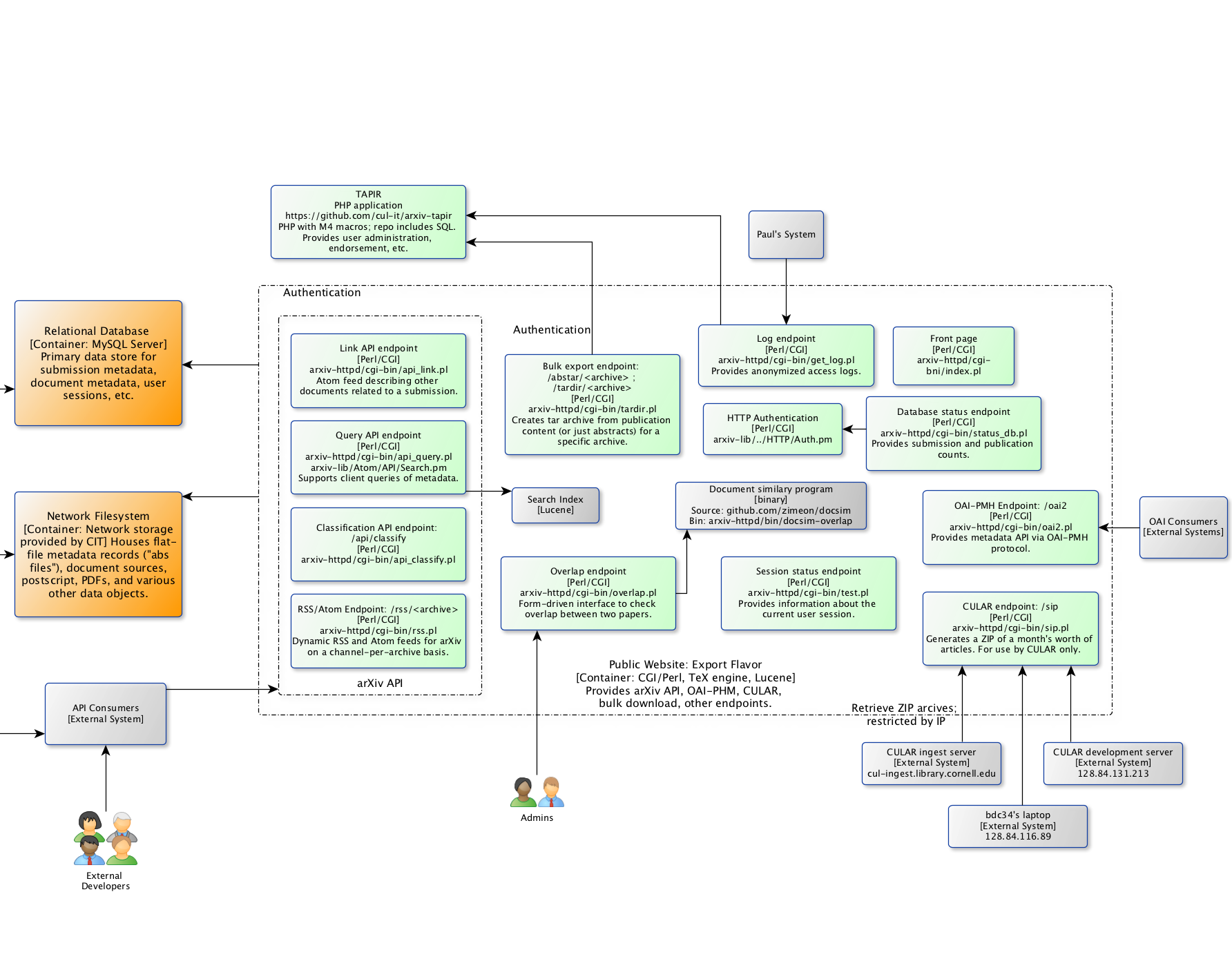
Fig. 5 Public website, export flavor.¶
In addition to Perl CGI scripts, a lucene search index backs the search and RSS/Atom feeds.
In the export flavor, a custom binary program called docsim backs the overlap endpoint.
Some of the endpoints in the export flavor rely on session data provided by the TAPIR application in the Submission & Moderation Platform.
Automated announcement & Email Notification System¶
Announcement occurs five days each week: once per day, any submissions that are in an appropriate ready state are transitioned to a published state. This involves minting a new arXiv identifier, moving submission content to appropriate locations on the network filesystem, indexing the announcement, and generating flat-file metadata records that are used by the browse flavor of the public website.
During this process, email notifications are triggered that alert subscribers to new content in their areas of interest. Although we can think about the notification process as largely separate from announcement, in the current implementation the announcement and email alert systems are tightly coupled: their subsystem procedural components are tied together in a single scheduled task designed to run daily on the main web server.
Components¶
As noted above, the announcement and email alert systems are tightly coupled: their subsystem procedural components are tied together in a single scheduled task designed to run daily on the main web server. In addition to indicating interactions among components within these systems, the order of execution is also indicated with dotted lines.
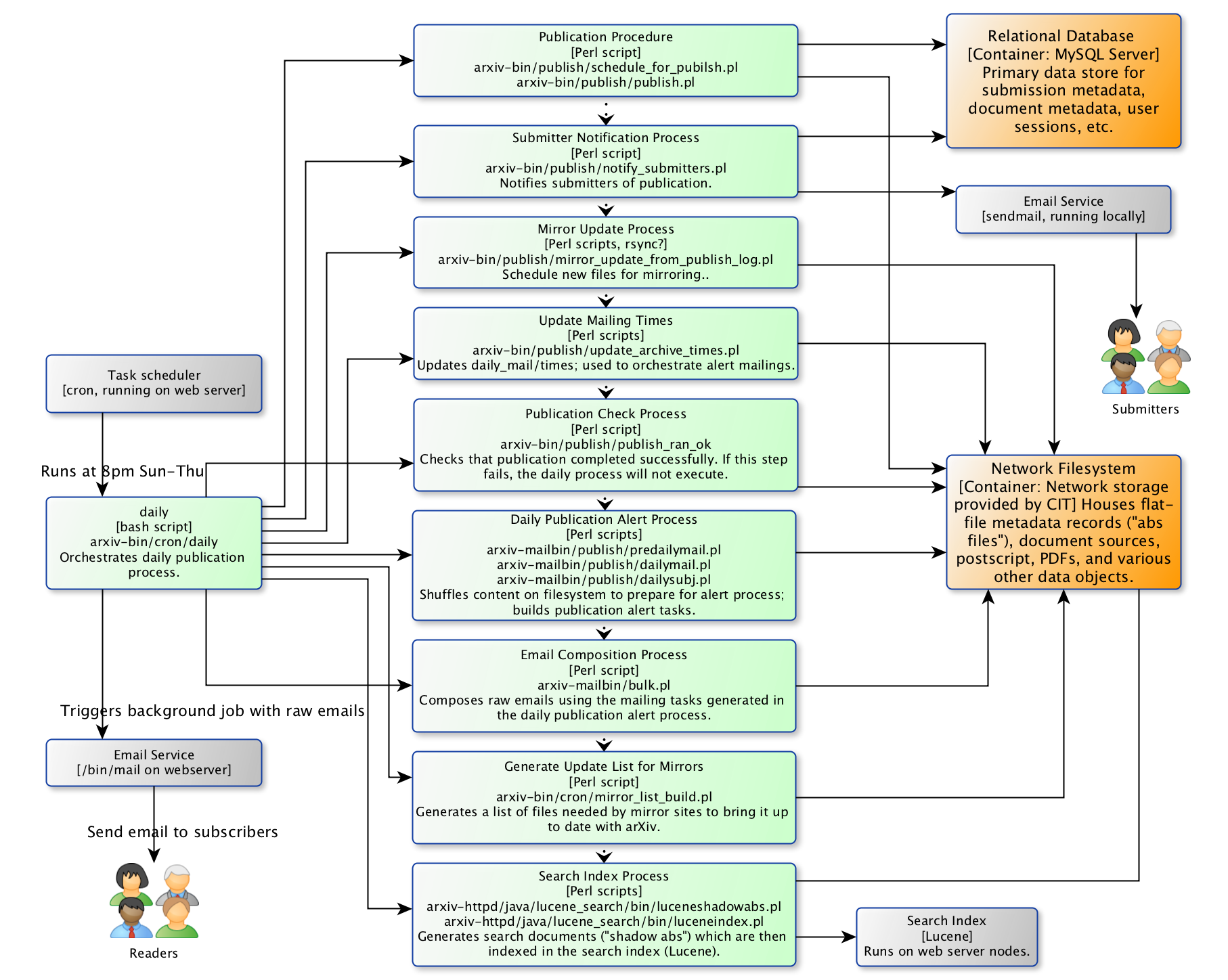
Many of the steps in the announcement and notification process involve reading from and writing to the network filesystem. Early in the process, submission metadata is retrieved from the relational database. Those metadata are used to generate a flat-file metadata record (the “abs file”), which is put in place to provide the abstract view on the public website.
Notifications about announcement are sent to submitters using the local sendmail service. The notification service relies on a filesystem-based registry of email subscriptions. The system articulates a collection of raw emails organized by subject classification, and passed to the local system email service (/bin/mail).
The announcement process is also responsible for updating the Lucene search index.