Solution Strategy¶
In the Introduction & Goals we noted that:
The existing arXiv system is highly stable in that it provides a consistent set of core services with high availability. The codebase that supports that system has grown organically over a long period of time, with varying and sometimes unclear architectural visions. The technology on which arXiv is built is variously antiquated or (due to cultural changes) obscure. As a joint result of those factors, it is exceedingly expensive to develop the existing codebase to fix bugs, address feature requests, and keep pace with end-user expectations of usability and security. The principal challenge of classic renewal will be to progressively evolve arXiv into a modern and architecturally sound software system while maintaining the level of consistency and availability of the system as a whole.
By virtue of its history and high-level design, arXiv has three notable advantages that are unique in the current e-print space and that can directly inform our solution strategy:
The arXiv user base is highly satisfied with the existing service, despite (and, in some cases, because of) its dated UI and limited data model. If little or no user-facing changes were made to the core services, a substantial portion of the user base would remain satisfied. For details, see the arXiv User Survey Report.
There already exists a large ecosystem of researchers and web developers who are generating online tools based on arXiv content. This includes recommender systems, search tools, text mining, social media “alt metrics”, etc. This relieves pressure to add trendy bells and whistles to arXiv itself. At the same time, the popularity of arXiv motivates external groups (e.g. journals, authoring platforms) to collaborate on integrations that add value for users.
The separation of submission/moderation processes and discovery/access, both in time and in the way that data are stored, transformed, and accessed, impart many features associated with modern distributed software systems. Although the current implementation of the system is extremely complicated (poor separation of concerns, breakdown of abstractions), the quasi-distributed nature of the current system lends itself to incremental re-development.
Those observations suggest that we can maximize the long-term impact and efficiency of arXiv classic renewal by:
Incrementally re-engineering existing core systems around modern technology with a consistently-applied modular/distributed architecture.
Prioritizing the availability of high-quality data and services for programmatic consumption via well-documented APIs, and cultivating relationships with external developers and collaborators, over significant development of new functionality.
Many of the limitations of the existing system will be alleviated throughout classic renewal as a side-effect of adopting modern technologies. Other limitations can be addressed, and new features introduced, during the process of re-engineering various parts of the system. Where substantially new functionality is identified for development, the adoption of a clear architectural model with modern technology will allow those features to be developed much more rapidly.
The whole development team will participate in NG, and strategically address stakeholder requests for bug fixes and new features while incrementally re-engineering components of the system.
Prioritization of development effort is subject to change in response to stakeholder input, conveyed via the Scientific Director and Stakeholder Relations Manager, and at the final discretion of the arXiv executive team.
High-level architectural features¶
In the introduction, we identified seven key objectives for the NG architecture. In this section, we describe high-level architectural decisions based on those objectives.
Microservices architecture¶

The classic arXiv code-base is what you might call a spaghettilith: a monolithic system in which, with the passage of time, what were once useful abstractions have become tangle of indirection and concerns. While stable and performant, the platform is exceedingly difficult to develop in this state.
Concerns about evolvability and minimizing complexity for developers are major drivers for our transition to more service-oriented architecture. In short, our goal is to never undertake arXiv-NG 2.0. One way to look at this transition is that we are moving integrations from buried deep within the spaghettilith, or at the database or filesystem level, up to the level of HTTP.
The arXiv.org classic renewal will proceed by incrementally decoupling and re-engineering subsystems of the existing system toward a more fine-grained, loosely-coupled architecture. In contrast to the classic arXiv system, which is composed of a small number of applications with broad concerns running in a shared environment, the NG architecture distributes responsibilities across a larger number of applications with narrow concerns.
The NG architecture and its implementation are guided by the following principles:
- Abstraction
The inner workings of a subsystem will be screened off by the API that it presents to the rest of the system.
- Independence.
It must be possible for a single developer to implement, test, stage, and deploy new features in a specific subsystem with minimal coordination with functionally unrelated parts of the system. The development of shared core libraries that implement business logic (such as the existing arxiv-lib library) will be avoided. The focus is on providing valuable functionality within the domain of the subsystem.
- Granularity.
Each subsystem will provide distinct functionality with a specific set of concerns. Generally, those bounds of concerns will be defined by specific data products (e.g. PDFs, search, cited references) or business processes (e.g. submission, Announcement).
- Normalization.
To the extent practicable, redundant operations will be encapsulated as separate subsystems/services. For example, full text extraction is necessary for a wide range of operations (e.g. indexing for search, classification, overlap detection), and will therefore be treated as an independent subsystem. Normalization will be counterbalanced by performance considerations, such as optimizing lookup of related data.
In a microservices architecture, responsibility for specific functionalities and resources within the system are parceled out to independently deployable applications. Instead of integrating those functional parts of the system within the application codebase through procedure calls, services are integrated at the HTTP layer via REST APIs and event notification.
Incremental decoupling¶
The arXiv classic renewal process will proceed according to the general iterative procedure outlines below. The rationale for this approach is based on the constraint that new or re-engineered subsystems must maintain integrations with the classic (legacy) system, and not disrupt existing functionality and user experience, and the recognition that substantial isolated development without attention to integration introduces significant risk and expense.
Prioritization. Identify subsystems that can be isolated from the existing system without severe side-effects, and whose improvement will add significant value for stakeholders.
Identify minimum integrations. Identify critical integrations of each subsystem with the existing system. This involves de-abstraction of each subsystem in order to identify integrations with other subsystems (e.g. database operations upon which other subsystems depend), as well as characterizing the behavior of the subsystem from the perspective(s) of users.
Re-engineer around behavior and quality goals Develop a new subsystem that sufficiently preserves the user-facing behavior as well as the minimum viable integration with the existing system. Those subsystems will adhere to an internal architecture that “screens off” the implementation details of those backend integrations in order to minimize the cost of future changes. The objective of this step is to create space to re-engineer the core of the subsystem without disrupting the rest of the system or requiring dramatic infrastructure changes. This may involve isolating state in a new datastore.
Local deployment The new subsystem will be deployed on existing infrastructure. In most cases, this will involve replacing the relevant CGI routes with proxy routes to the subsystem (a Flask-based web application) via Web Server Gateway Interface (WSGI). Subsystems that do not replace existing functionality may be deployed directly to AWS.
API gateway integration Characterize resources that should be exposed via the arXiv API, write documentation for those resources, and implement the appropriate configuration at the gateway.
Migration In coordination with other parts of the system, migrate the subsystem itself to separate cloud infrastructure.
The eventual outcome of classic renewal will be a modular system running mostly or entirely on cloud infrastructure.
Building blocks¶
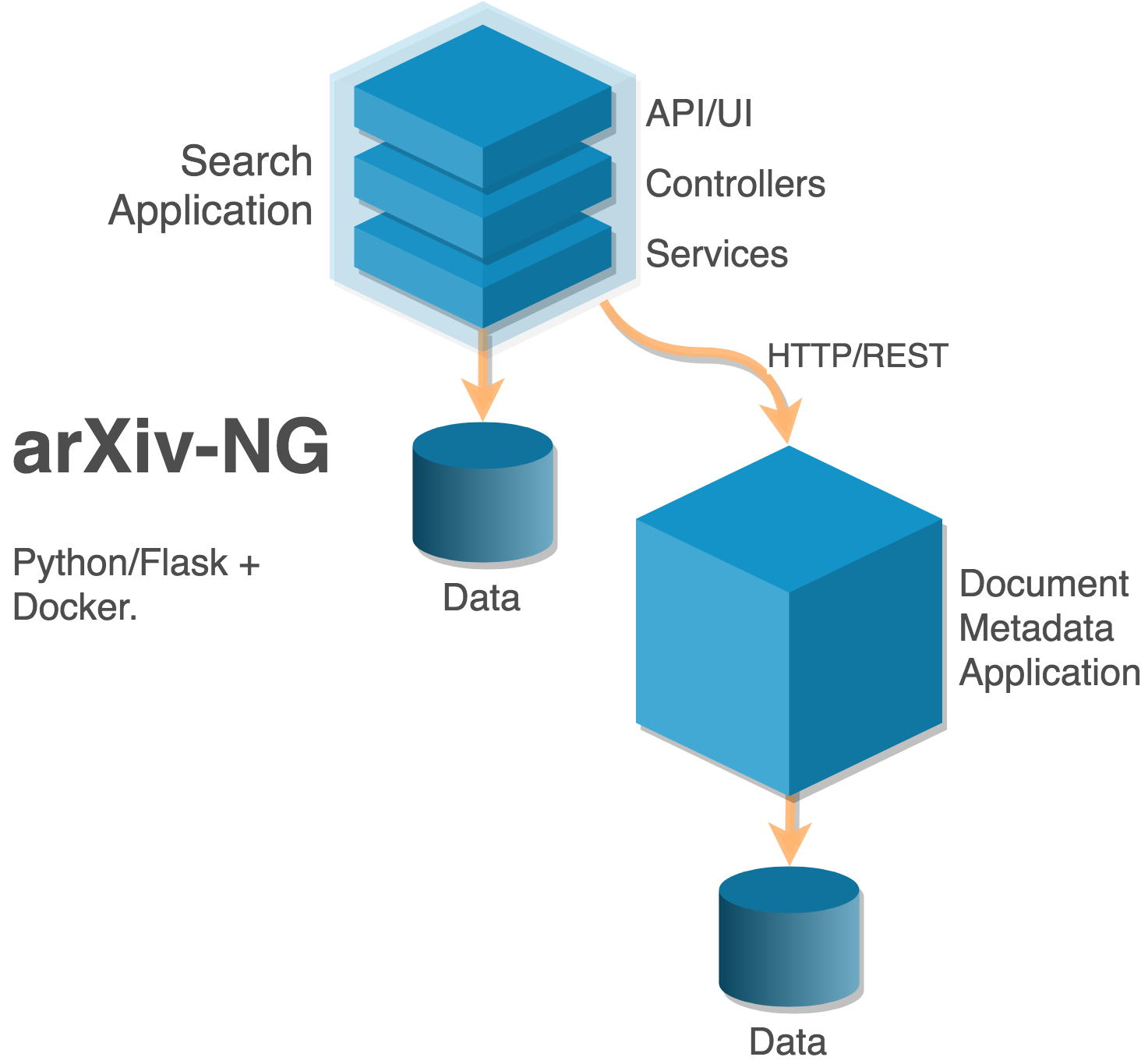
In order to achieve the combination of synchronous and asynchronous behaviors required by the moderation and announcement processes, the arXiv NG architecture distinguishes between two main types of building blocks that are implemented across the system: services, web applications that provide APIs and user interfaces within a limited scope, and agents, which coordinate higher-level operations in response to system events.
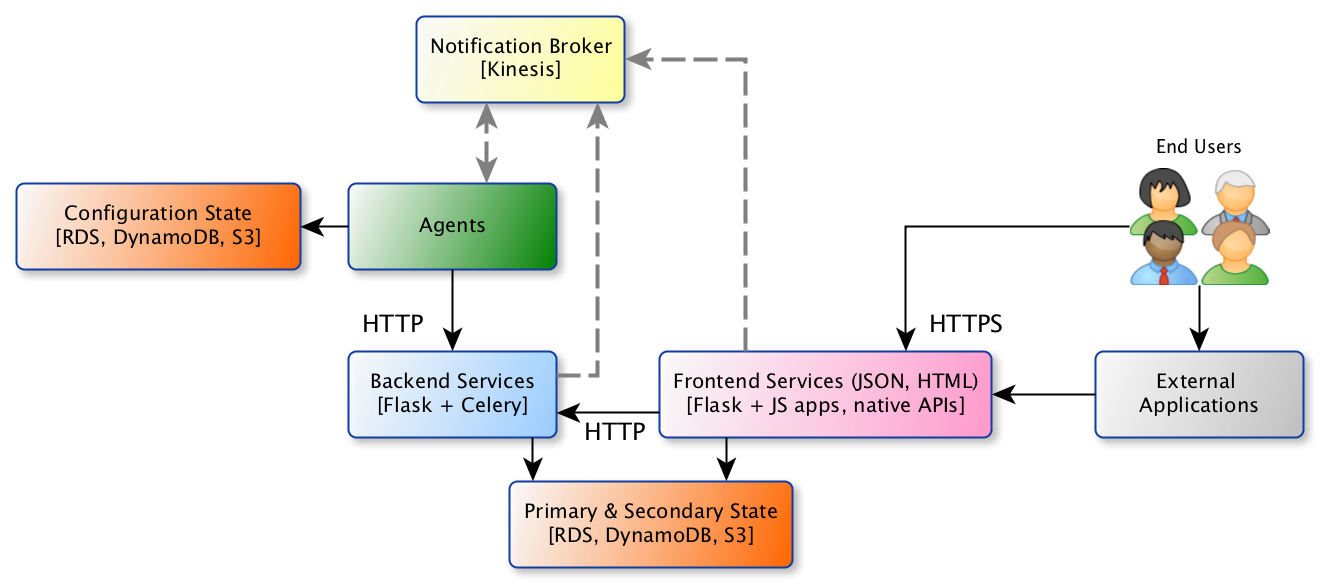
Fig. 9 Generic building blocks in the arXiv NG architecture.¶
Services¶
Services are web applications that provide a limited set of closely related functionalities, usually centered around a single resource type or an aggregate of resource types.
In some cases, services will be stateless: the service will simply accept some data, perform a transformation, and return some other data. An example of a stateless service is the TeX compilation service: it accepts a source package, compiles the source, and returns a PDF and the compilation log.
Other services will be stateful: they will provide RESTful APIs and/or interfaces to interact with resources, and rely on an associated data store (e.g. a relational database, a NoSQL data store, an S3 bucket) to persist those resources. Although there may be exceptions, other services or agents will generally access the data in those data stores by way of the abstract resources exposed by the service that relies. For example, the submission service exposes APIs and interfaces for creating and updating submissions, and persists submission content and metadata in an S3 bucket and a data store. Other services will access those data by calling an API provided by the submission service.
Services can come in three flavors. A single service may implement more than one flavor.
- Frontend UI services
These services provide user interfaces, generally rendered HTML and CSS. They make up the public face of arXiv for most end users.
- Frontend API services
These services provide programmatic access to arXiv content, and privileged interventions, by known external clients. This includes APIs like the RSS and OAI-PMH feeds, the search API, and submission APIs.
- Backend services
These services provide interfaces for use by other services and agents within the arXiv system. For example, services that support autohold and classification for the submission system are not exposed externally.
In general, each backend service has one primary concern. For example, the plain text extraction service is solely concerned with extracting plain text content from a PDF. The granularity of that concern is open to some negotiation, driven by anticipated use-cases. For example, if the task of building a PDF from TeX and the task of building a PDF from postscript always occur in the same contexts (a submitter wishes to build and preview their paper), and have similar dependencies, then it would be reasonable to treat them as part of the same concern, namely building a PDF from submission source.
Frontend services may produce system event notifications. For example, moderator actions in the moderation service will generate events to be handled by the moderation agent.
Frontend services may call backend services. For example, when a submitter triggers compilation of their PDF from TeX, the front-end service will provide a view that polls the backend service for the task state and presents that information to the user (e.g. via a progress bar).
Agents¶
Agents are programs that execute in response to system events in order to coordinate activities across more than one service. They are responsible for coordinating asynchronous activity in the system by consuming and producing event notifications. Agents utilize backend services to advance system activities like classification, Announcement, and enrichment.
Agent notifications are handled by a central notification broker (e.g. AWS Kinesis). Each notification…
Belongs to a specific topic (stream) to which agents may subscribe.
Should concern a single data object, such as a submission, Announcement, or user.
Should include a lightweight data payload specified by a JSON schema associated with the topic.
For example, when a PDF is successfully created and stored for a new Announcement, the responsible agent might produce a notification to the “PDFIsAvailable” stream with details about the corresponding paper. Any agent that is interested in PDFs of published papers, such as the email subscription agent or the plain text extraction agent, would consume that notification and begin coordinating service operations accordingly.
Integration¶
Whereas subsystems in classic arXiv interact mainly through procedural calls and shared data stores, the arXiv NG architecture shifts most integrations to the level of HTTP APIs. This facilitates better isolation of subsystems, enhanced monitoring of subsystem interactions, and greater flexibility when scaling.
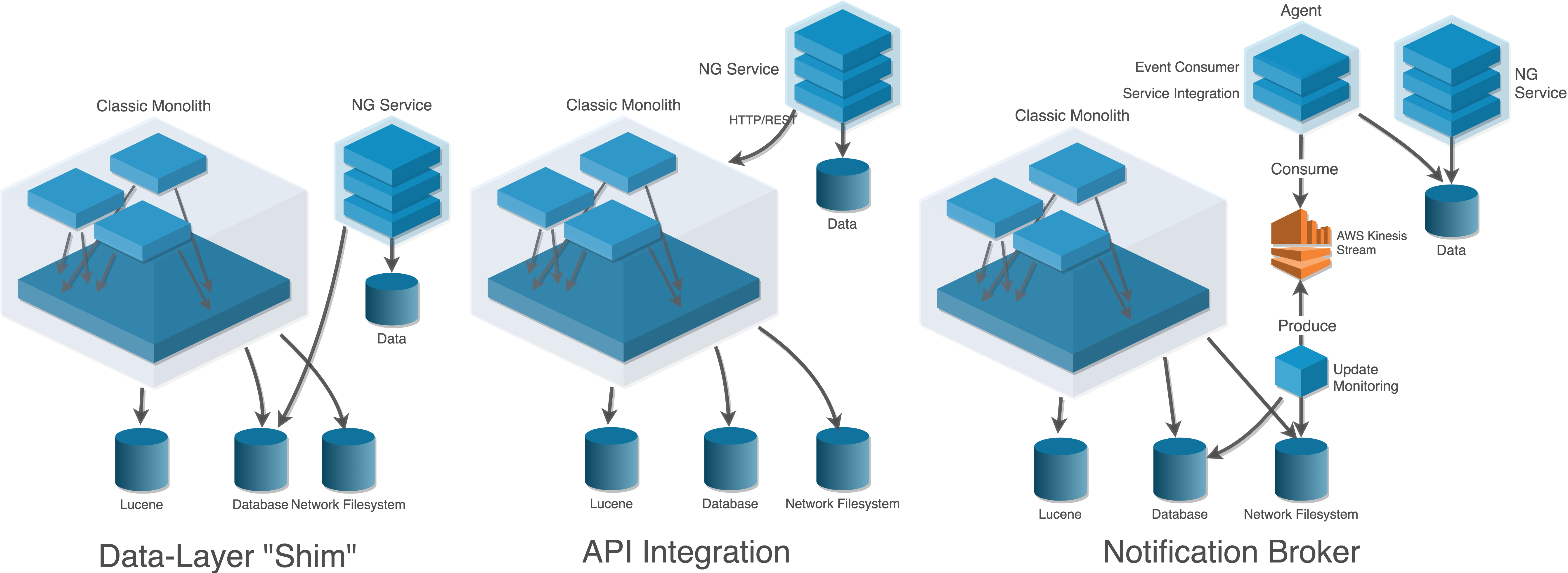
Fig. 10 Integration patterns for arXiv-NG.¶
As we carve off bits of the classic system, we leverage three general integration patterns.
Data-layer “shim”¶
In some cases, it is unavoidable that we provide minimal access to the database or file-system layers of the classic system. We call this a “shim,” in that it provides a temporary integration that gives us some space to develop the re-engineered service. In many cases, those bits of the database or file-system under the purview of a service will eventually be carved off from those massive pools of state.
API integration¶
API-level integrations involve introducing a lightweight Perl controller in the classic system that provides HTTP-level access to the required data. This is preferable to a data-layer shim: although the Perl implementation of the API will change, the API itself becomes a durable part of the NG architecture.
Many services, and most stateful subsystems, will expose data and functionality to machine clients via RESTful APIs. REST APIs on services and data stores provide an internal point of integration for other subsystems, as well as public functionality for API consumers.
Each service exposes a distinct set of endpoints for frontend UIs, frontend APIs, and backend APIs. For API routes, each service provides a formal description of the resources and actions that it exposes (ref) that is stored and versioned along with the service itself.
Each of those three sets of routes is exposed on the network via a gateway/ingress.
An ingress for frontend UI routes will handle end-user traffic. This is the public face of
arxiv.org, rendered as HTML/CSS.A gateway for external API consumers will handle frontend API traffic from authorized clients to
api.arxiv.org.An internal gateway that handles backend service traffic. This gateway is not accessible to the outside world.
System events & notification¶
A third and final pattern is a publish-subscribe pattern leveraging AWS Kinesis. In this pattern, important messages (e.g. a new paper) are generated by a component in the classic system, and distributed over a “topic” or “stream”. Those messages are consumed by NG components called “agents”. We use this pattern to keep our search index up to date as papers are published or updated.
Agents facilitate high-level operations that span services, and run outside the context of requests to the frontend UIs and APIs. Agent activity is coordinated using system event notifications disseminated by a central broker.
Each event notification is an instance of a specific event type; each event type is handled by a separate stream. Agents consume events of a particular type by subscribing to its respective stream.
New event types will be introduced throughout the implementation of the NG system. A valid event type transcends the context of a specific service, and is free of details particular to the implementation of the service(s) that produce them.
Both agents and services may produce event notifications.