Submission Subsystem¶
The submission and moderation subsystem encompasses the applications, data, and processes by which e-prints enter arXiv and are prepared for announcement. In other words, (almost) everything that happens to an e-print prior to announcement takes place within the context of the submission subsystem.
The scope of this subsystem begins at the multiple interfaces by which e-prints are submitted to arXiv, encompasses a wide range of quality assurance and moderation activities, and ends at the “scheduling” of an e-print for incorporation into the canonical record and announcement to public stakeholders.
In related domains (such as journal publication) the procession through a submission process to ultimate publication involves the active participation of multiple actors. For example, editors, reviewers, and others must take explicit action for a submission to make its way to publication.
In contrast, the arXiv submission subsystem operates passively, much like a series of filters. Some of those filters are programmatic, and the submitter may be required to take several actions to satisfy their parameters (e.g. well-formed metadata, usable TeX source). An additional layer of filtering occurs within the context of moderation, in which individual human moderators and administrators may intervene on an e-print to block or delay its announcement (possibly requiring further action by the submitter). But in the absence of moderator or administrator intervention, an e-print will proceed automatically to scheduling and eventual announcement provided that programmatic filters are passed.
Contents
Context¶
A submission is a scientific text (e.g. a research article) accompanied by descriptive and procedural metadata that has been provided by a submitter for the purpose of announcing the work as an e-print on the arXiv platform.
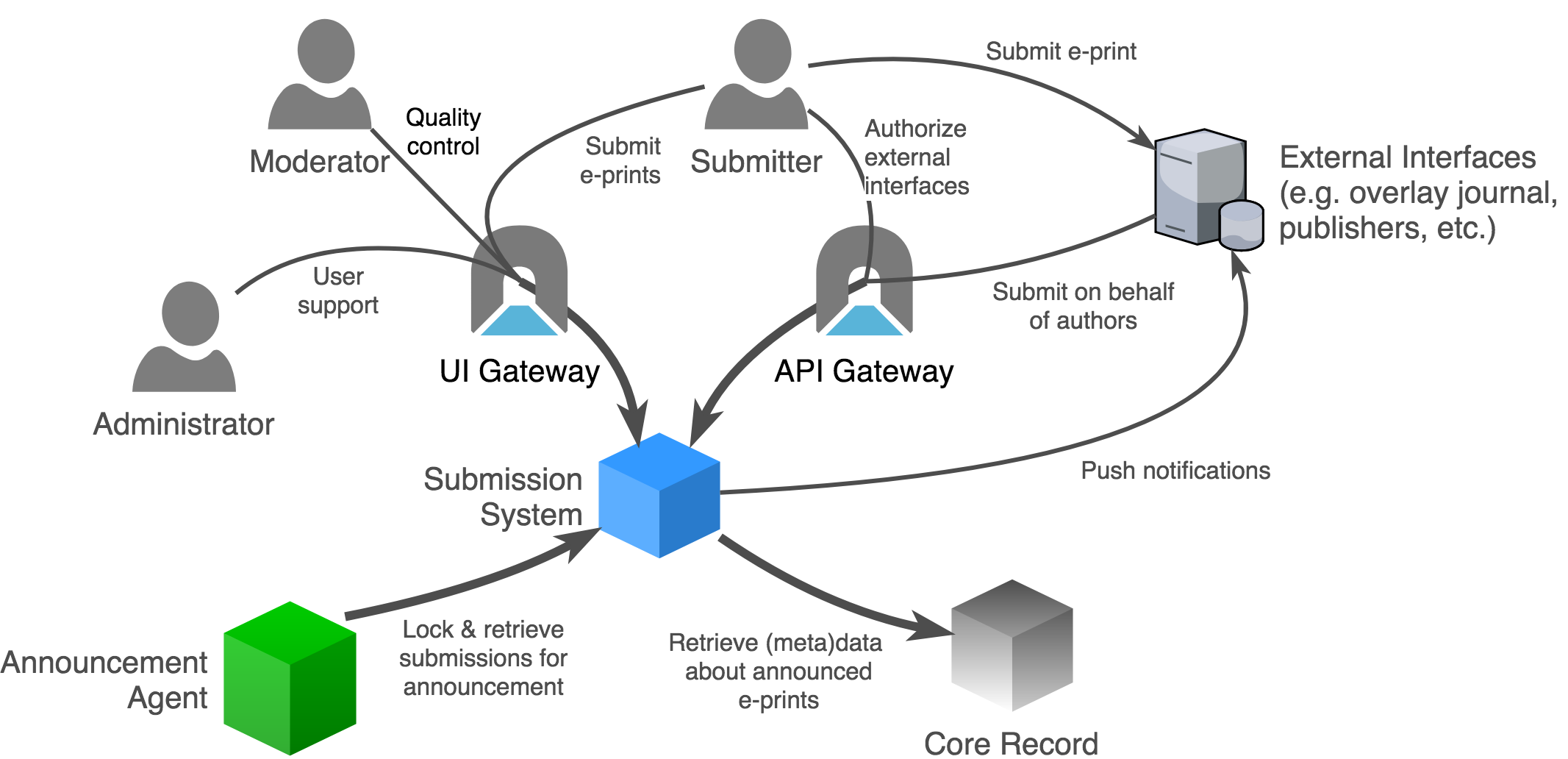
Fig. 13 System context for the arXiv submission system.¶
Submitters¶
The submitter is the primary human actor that originates an e-print submission and holds the ultimate responsibility for the procession of their e-print to scheduling for announcement. Note that the submitter may or may not be an author of the e-print.
Examples of submitters:
An author. The typical submitter is an author of a scientific work who intends to share that work with peers via the arXiv platform.
A proxy for individual users, acting on behalf of an author. For example, submissions originating from large scientific collaborations may be provided to arXiv by support staff rather than authors.
An editor of conference proceedings or other collections (i.e. a bulk proxy). Authorized conferences may deposit works from their proceedings in arXiv. This may occur through specialized web interfaces, or via APIs.
Each of these types of submitters will hold arXiv user accounts, be authenticated with arXiv, and hold the required authorization(s). Examples of required authorizations include:
Endorsement to submit to a particular subject area within arXiv.
Permission from arXiv to act as a bulk proxy, e.g. for conference proceedings.
Permission from another arXiv user to submit to arXiv as their proxy.
From the perspective of an end user, submissions to arXiv are composed of a source package (e.g. a LaTeX source, or a PDF) and a small set of descriptive metadata.
The submitter uploads a source package, enters descriptive metadata, and takes any required procedural steps (e.g. confirming a preview of their e-print, agreeing to terms of submission) necessary to fully prepare their submission. The submitter may also return to the platform to follow up on problems that arise during quality assurance checks.
Submitter concerns¶
Depending on the context, submitters may hold a combination of several or all of the following objectives:
Increase the visibility of research results within their field, discipline, or general public.
Obtain early feedback from scientific peers about preliminary research results, in order to try out new ideas and/or improve the quality of an eventual peer-reviewed paper.
Establish priority for a scientific idea.
Submit a paper for peer-review and publication in an overlay journal.
Make an accepted or published scientific paper freely available to readers.
Embed more ephemeral scientific outputs into the scientific record (e.g. conference papers).
Ensure long-term availability of scientific outputs (i.e. arXiv plays an archival function).
Moderators¶
Over 160 volunteer **moderators** monitor the stream of submissions that flow through their particular subject area on a daily basis. An overview of arXiv moderation system can be found on the arXiv help site. Moderators screen submissions based on their scientific expertise for content that does not appear to be appropriate for announcement on arXiv, and may take a variety of actions in support of that goal.
Moderators have visibility onto both submissions and the results of automated processes, and may intervene on submissions to implement moderation policies and/or require further intervention by the submitter. This may include:
Proposing reclassification of submissions.
Place a submission on hold.
Make comments or other annotations for peer moderators and administrators.
Moderator concerns¶
Moderators participate in arXiv in order to serve the scientific communities of which they are a part. Toward that end, their concerns include:
Reliably and efficiently identify problematic submissions.
Appropriate, expedient, and transparent handling of problematic submissions.
Clear and responsive communication with arXiv user support staff (admins).
Coordination with other volunteer moderators in their domain.
Effective use of moderator time.
API consumers¶
The primary use-case for interacting programmatically with the arXiv submission subsystem is the provider of external platform acting on behalf of an individual author.
In this case, the operator of the API consumer will have already obtained permission from arXiv to provide an alternative interface for submission, and the author will have granted explicit authorization to the platform via a three-legged OAuth2 workflow.
API consumers may actively create and update submissions, and may interact directly with utility services such as the compilation service. They may also register webhooks with the webhook service, so that they can receive notification of events related to submissions of interest.
Other arXiv services¶
During the daily announcement process, the Announcement agent retrieves information about announcement-ready submissions. The announcement agent moves submission content and metadata into the appropriate storage facilities, transitions the state of announced e-prints, and triggers downstream processes via the notification broker.
Some processes in the submission system require information about past arXiv papers. For example, classification, overlap detection, and other QA/QC services will keep themselves up to date by consuming metadata and content from announced e-prints in the canonical record.
Key requirements¶
Several key requirements emerged from the consultation and planning process for arXiv NG:
The subsystem must sensibly incorporate input from, and synchronize the activities of, a variety of human and non-human agents.
It must be possible for administrators to audit all changes to submission state in the subsystem (e.g. by submitters, moderators, automated processes, etc).
Administrators and moderators must be able to configure automated rules and processes.
The subsystem must support future development of potentially many alternative interfaces for submission and moderation, including interfaces developed and operated by trusted third-parties.
The subsystem must be able to support a high volume of activity. We currently process around 11,000 submissions per month (early 2018), and expect that to grow at least 10% per year.
The subsystem must make it easier to support future operational and policy changes around submission content, quality assurance, metadata, and other areas of concern.
Solution strategy¶
The classic arXiv submission system was implemented as a conventional MVC-style web application (Perl/Catalyst framework) on top of a set of abstractions that encapsulate database and filesystem access as well as a variety of heuristics built up over time to handle new scenarios and features. This has become increasingly difficult to extend further.
To address the key requirements enumerated above, the high-level architecture for the NG submission subsystem is comprised of the following major parts:
The core data architecture is built around a stream of submission-related events, which describe the mutations of a submission from its creation through announcement. The event model is implemented in the core submission package, which handles storage of events, interoperability with the legacy data model, and propagation of events for consumption by other services in the submission subsystem. The event model captures the core domain logic of submissions, including input validation for each event type.
Submission interfaces are implemented as independent applications that mutate submissions by generating events. Interfaces perform basic input validation, e.g. by translating event model exceptions into informative messages, and disallowing invalid input.
Automated policies and procedures are implemented in the :mod:`agent`. This application listens to submission events, and carries out asynchronous processes that may further mutate submissions via events.
Major functional components of the classic submission system are decomposed into independent services. These backend Utility services are generally agnostic about the submissions themselves. This includes classification, overlap detection, compilation (TeX, PS), and upload/file management. These services may be invoked by the interfaces and/or agent as needed to carry out submission processes.
Model & drivers¶
This section documents a working conceptual model of the arXiv submission subsystem, focusing on the prevailing concerns and drivers that shape the design of its technical components. The purpose of this section is to provide a common frame of reference for project participants as questions about policies, procedures, and system design arise.
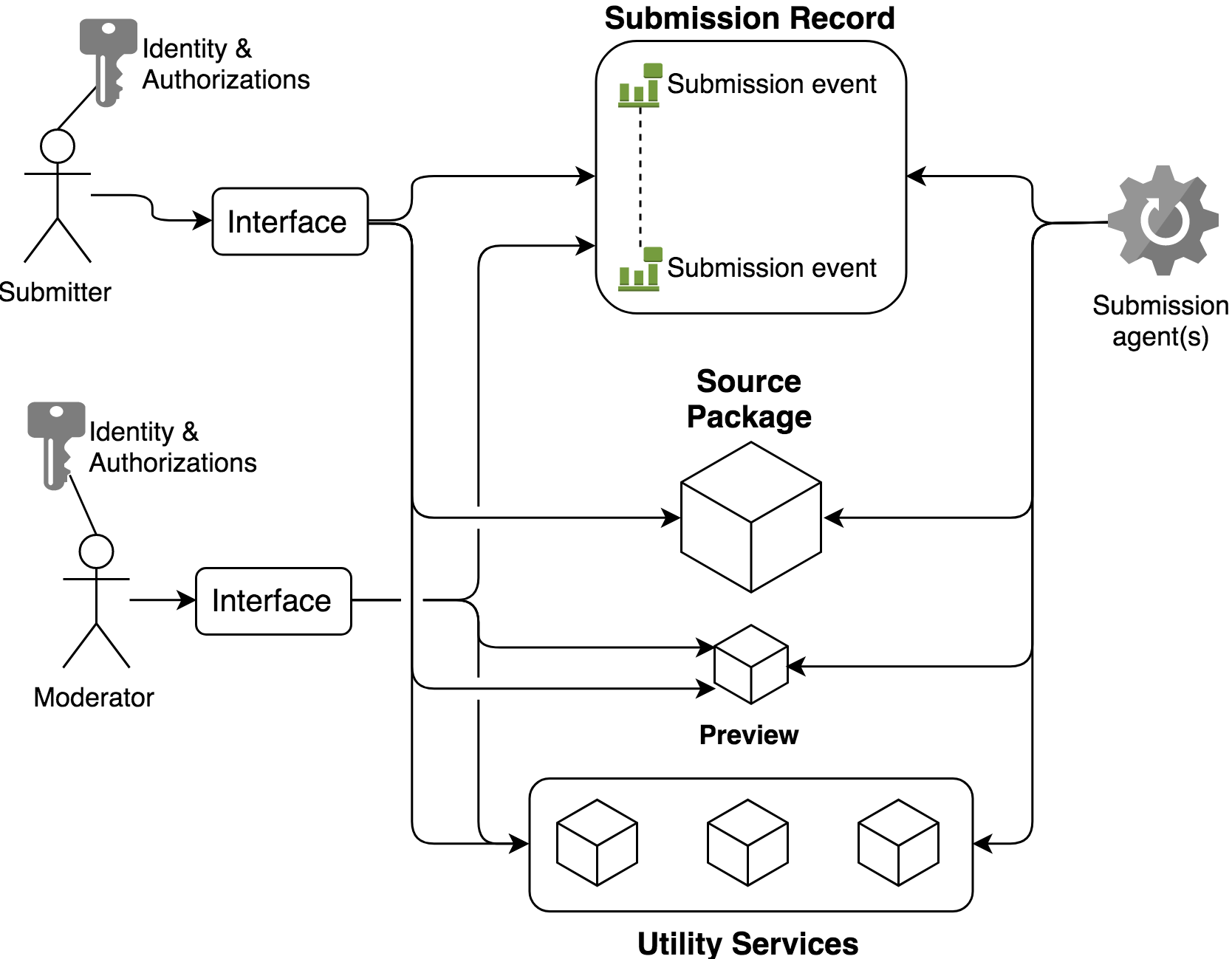
Fig. 14 Working conceptual model of the arXiv submission subsystem.¶
Submissions¶
A submission is an abstract object that arises from a collection of content files (the “source package”), procedural and descriptive metadata, and additional annotations generated by moderators, administrators, and automated systems prior to announcement. A submission generally represents a single scientific work, provided to arXiv for announcement and dissemination to other researchers and for free public distribution.
Submission content and metadata are treated separately in the subsequent sections.
Source package¶
The source package is a collection of files, such as a set of TeX sources, images, and ancillary files, that comprise or will generate a scientific paper for distribution. In the classic system, the source package and the submission itself are tightly coupled, in that there is a one-to-one correspondance between a submission and a source package. In the NG submission subsystem, the source package is identified independently of submissions, in order to facilitate more complex workflows.
A source package is identified by a numeric source identifier (or upload identifier), and by a checksum of the package contents. Any service or process that operates on a submission source package will do so in reference to both the source identifier and the specific state (represented by the checksum) of the source. This helps to ensure consistency when multiple systems or actors are performing activities in reference to the source package, which may change over time as files are added, amended, or removed.
Forms of submission content¶
Submitters provide content to arXiv in one of several forms.
The most common form is a TeX source package, containing sources for the manuscript, bibliographic references, styles, images. Ancillary content, such as data or other supporting materials.
Submitters may alternatively provide a finalized PDF. In limited cases (e.g. conference proceedings indices) HTML-only submissions may be permitted. Other content types may be supported in the future.
Accession of content during submission inevitably involves competing interests of the submitter and other stakeholders.
The submitter…
Wants to provide a manuscript in a form that is closest to what they will submit to a journal or conference.
Wishes to minimize the amount of arXiv-specific tweaks and changes required.
Wishes to include as much arbitrary ancillary content as they feel is appropriate to support their manuscript.
Wants readers to see the manuscript in the same form that they do on their own computers. I.e. if their TeX source compiles a particular way on their own system, the submitter would prefer that it compile in the same way on arXiv.
Competing drivers include:
The cost (in terms of testing, troubleshooting, documenting) of supporting third party add-ons and macros for TeX creates some lag between the general availability of new TeX features and support in arXiv. This means that we must be somewhat selective about what we support.
The need to enforce content policies places some constraints on supportable file formats. For example, it is must be possible to extract plain text content from a submission.
Future readers have an interest in the ability to generate additional content types. This interest is frequently cited as a driver for continuing to encourage (if not require) that submissions be made in TeX format.
Readers have an interest in being able to obtain and read e-print content without road-blocks or delays. This puts constraints on the allowable size of e-prints, at least for the primary document that readers download.
There are real costs associated with overall volume of content stored by arXiv. While these costs continue to come down, this continues to be a driver for limits on submission content size that cannot be wholly dismissed.
Security considerations place some limits on the ability to allow certain file formats in submissions.
Archival considerations call for the ability to ensure the long-term integrity of e-print content. This includes both the ability to ensure the bit-level integrity of submission files as well as the means of access to the content encoded therein. This may make some file formats less feasible to support than others.
Researchers and platform developers have an interest in the ability to extract plain text content from e-prints, in order to perform text mining. While this concern ought not override strong concerns of submitters and readers around general consumption, it is not an unimportant consideration.
Decisions about the design and implementation of software to support the accession and processing of content must take these and other drivers into account.
Handling of submission content¶
Handling of submission content is generally separated into three distinct activities, which may take place independently of the submission itself.
Upload/transfer of submission content files.
Processing of submission content.
Confirmation of the submission content as it will be displayed to readers.
Uploads¶
Uploading/transfer of the source package is the domain of the file management service. It involves accepting, versioning, sanitizing, and checking source files for suitability for processing and ultimate announcement. The lifecycle of a submission source package begins when a new upload workspace is created in the file management service and a new unique source ID is assigned. Submission source packages are generally retained so long as they are associated with a submission that has not yet been announced.
Every modification of the source package results in a new checksum, and therefore a new “version” of the source package. Submissions refer to source packages by both their unique source ID and a checksum, and subsequent operations involving content will always refer to the checksum in order to prevent inconsistencies.
Processing¶
Processing of the source package encompasses any transformations of the content that are required to generate the final representation of the work as it will be distributed to readers. The canonical example is processing of TeX sources to generate a PDF, using the compiler service. For non-TeX submissions, processing may simply involve the verification of the required file(s) in the source package.
The end result of processing should be the existance of a readable product (currently, a PDF) that can be previewed by the submitter. The preview is housed by the submission preview service.
Interfaces that implement a submission workflow must orchestrate processing, including deposition of the preview.
Confirmation¶
Confirmation encompasses the display of the final preview of the submission to the submitter, and a positive affirmation by the submitter that the preview is acceptable.
Two considerations are especially pertinent here:
The preview must be substantially identical to what readers will see after the work is announced. Small differences (e.g. watermarks) may exist, but the typesetting, figures, references, and other aspects of the display of the content must be indistinguishable from the eventual announced version.
In most cases, an explicit positive affirmation that the submitter has viewed and is satisfied with the preview should be obtained. This may not always be possible or appropriate, e.g. in the context of bulk proxy submissions. In the case that the submitter is an external platform acting on behalf of an individual arXiv user, the platform should be expected to guarantee that the user has viewed and affirmed the preview.
Affirmation of the preview is commemorated as an event in the submission record (below).
Submission record¶
The submission record is a complex object that represents a scientific work to be announced on arXiv. The submission record is identified by a unique numeric ID, and refers to a source package in the arXiv submission subsystem by source ID and checksum. During announcement, the submission record and its associated source package are incorporated as an e-print into the arXiv canonical record.
The classic system tracked information about a submission using an object-oriented data model in which the submission is represented by a collection of related entries in database tables. The advantage of such a representation is that it fits naturally into an object-oriented programming paradigm, and is a well-understood pattern for web application development. The downside of that approach is that coordinating activity among many actors operating on a single submission at the same time can become unweildy, difficult to audit, and difficult to extend.
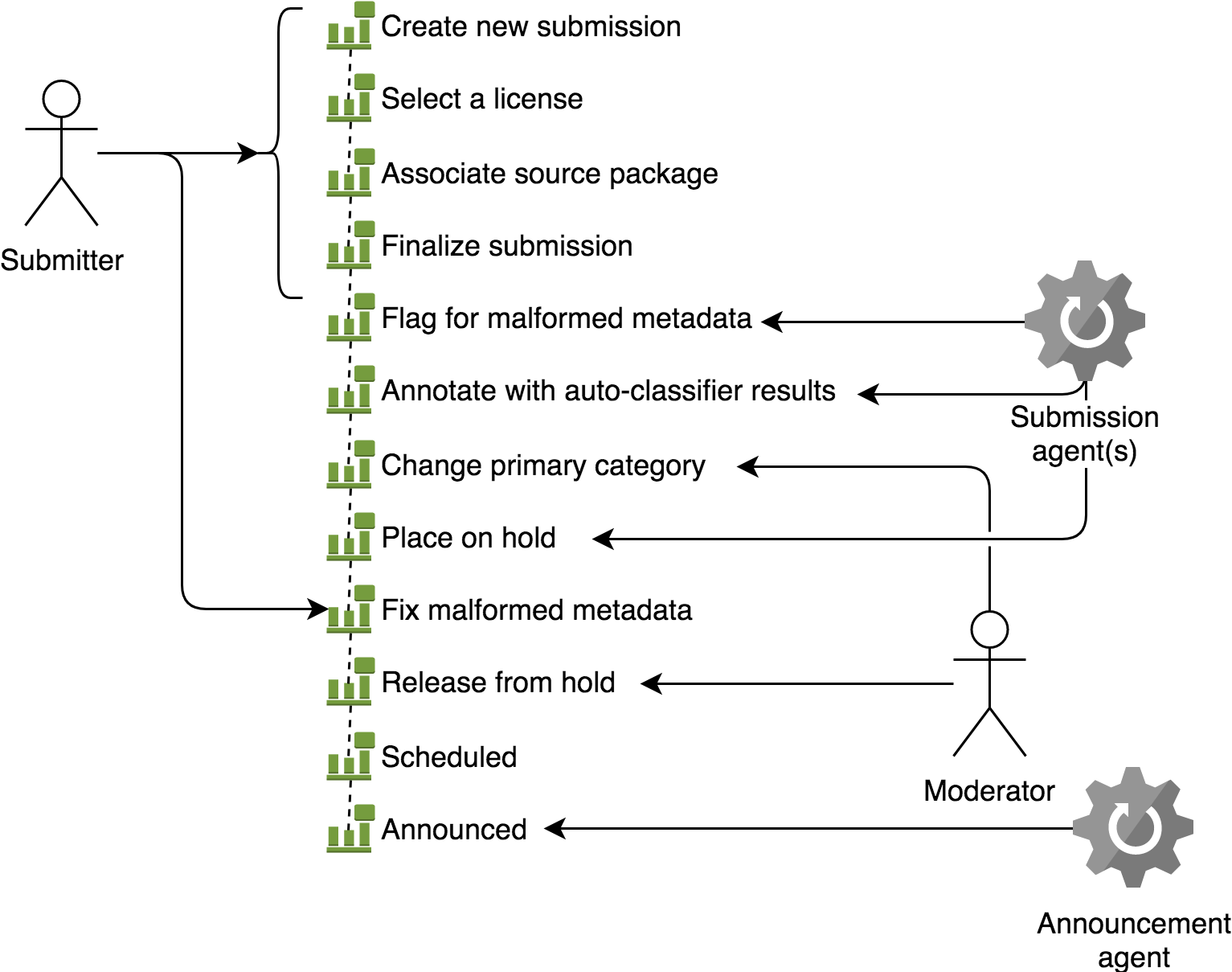
Fig. 15 The arXiv NG event-based submission record. Actors intervene on submission state by generating new submission events, which together describe the complete state of the submission.¶
The primary representation of a submission in the NG submission subsystem is a series of events that describe all of the changes that have occurred to that submission, starting with its creation. An event is comprised of some input data, such as input from the submitter, and an event type, which describes how those data are applied to the prior state of the submission to generate its subsequent state. The current state of the submission can be generated by “playing” those events in order from the beginning. Actors and systems intervene on submissions by generating new events, and may monitor submission activity by subscribing to and selectively processing those events.
Associated submission content¶
A submission is linked to its content by a reference to the identifer and checksum of a source package, usually housed by the file management service. Submission events are used to set and update that identifier and checksum. This may occur simultaneous to upload and modification of the source package, or subsequent to it.
In addition, affirmation of the submission preview (if required) is commemorated via a submission event.
In order for a submission to be finalized, scheduled, and eventually announced, it must:
Refer to a source package, and the checksum recorded in the submission record must match the current checksum of the source package upon retrieval.
Refer to a submission preview,
Submission interfaces¶
The purpose of each submission interface is to support the activities of a submitter as they move their e-print through the arXiv submission process. This encompasses “initial” submission activities, such as entering metadata and updloading content, as well as subsequent steps required for successful announcement of their e-print.
Current submission interfaces include:
The submission user interface, which supports authors and author-proxies submitting e-prints one at a time.
The SWORDv1 API, which supports editors of conference proceedings and other collections who deposit e-prints in bulk. This interface is slated for deprecation in the near future.
The submission API, which supports programmatic deposit of e-prints. This supports external platforms submitting on behalf of individual authors, and will also support programmatic bulk (proxy) deposit currently handled by the SWORDv1 API.
Additional interfaces may be introduced in the future, as distinct use-cases and/or submitter personas emerge.
From a submitter’s perspective, there are three principal areas of concern at both the time of initial submission and in subsequent actions prior to scheduling and announcement.
Procedural metadata, such as licensing, affirmation of terms.
Descriptive metadata, such as the title, abstract, author names.
Content, including both source files and the rendered product (e.g. PDF).
Each arXiv submission interface must deal with each of these three aspects of the submission in one way or another.
Procedural metadata¶
Procedural metadata are information about an e-print that exist primarily to facilitate announcement and dissemination by arXiv, rather than describing the content of the e-print per se. This includes:
Positive affirmation by the submitter of arXiv’s submission policies.
Selection of a distribution license for the work.
Attestation of authorship, or of permission to submit as a proxy for an author.
These metadata exist first and foremost to address the operational and policy concerns of arXiv, and only secondarily to address the concerns of the submitter.
These metadata may or may not require explicit input from the submitter. For example, submitters who are authors may select a distribution license explicitly at the time that they create a submission, whereas a bulk proxy submitter may have pre-selected a distribution license that is applied implicitly to all of their submissions.
Descriptive metadata¶
These metadata will almost always require input from a submitter for each e-print that is provided. Interfaces may collect these metadata as deemed appropriate for the use-cases that they support, and implement whatever means are necessary to translate those input into the corresponding submission events behind the scenes.
Orchestrating submission content workflows¶
In order for a submission to be scheduled and announced:
The submission must have an associated source package, indicated by an identifier and checksum. In the current implementation, the identifier is a numeric ID generated by the file manager service. Possible future extensions might use an URI, to allow for submission by reference to an external resource.
The checksum indicated in the submission record must match the current state of the source package.
The submission have have a confirmed preview, indicated by a source identifier, source checksum, and preview checksum. This preview must be available via the submission preview service.
Beyond those requirements, the specific means by which this state is achieved are not tightly constrained. For example, an interface might orchestrate all source content-related activities (upload, modification, processing, preview) prior to the creation of the submission record itself. Or, as in the example below, upload and processing steps may be interleaved with other steps in the submission process.
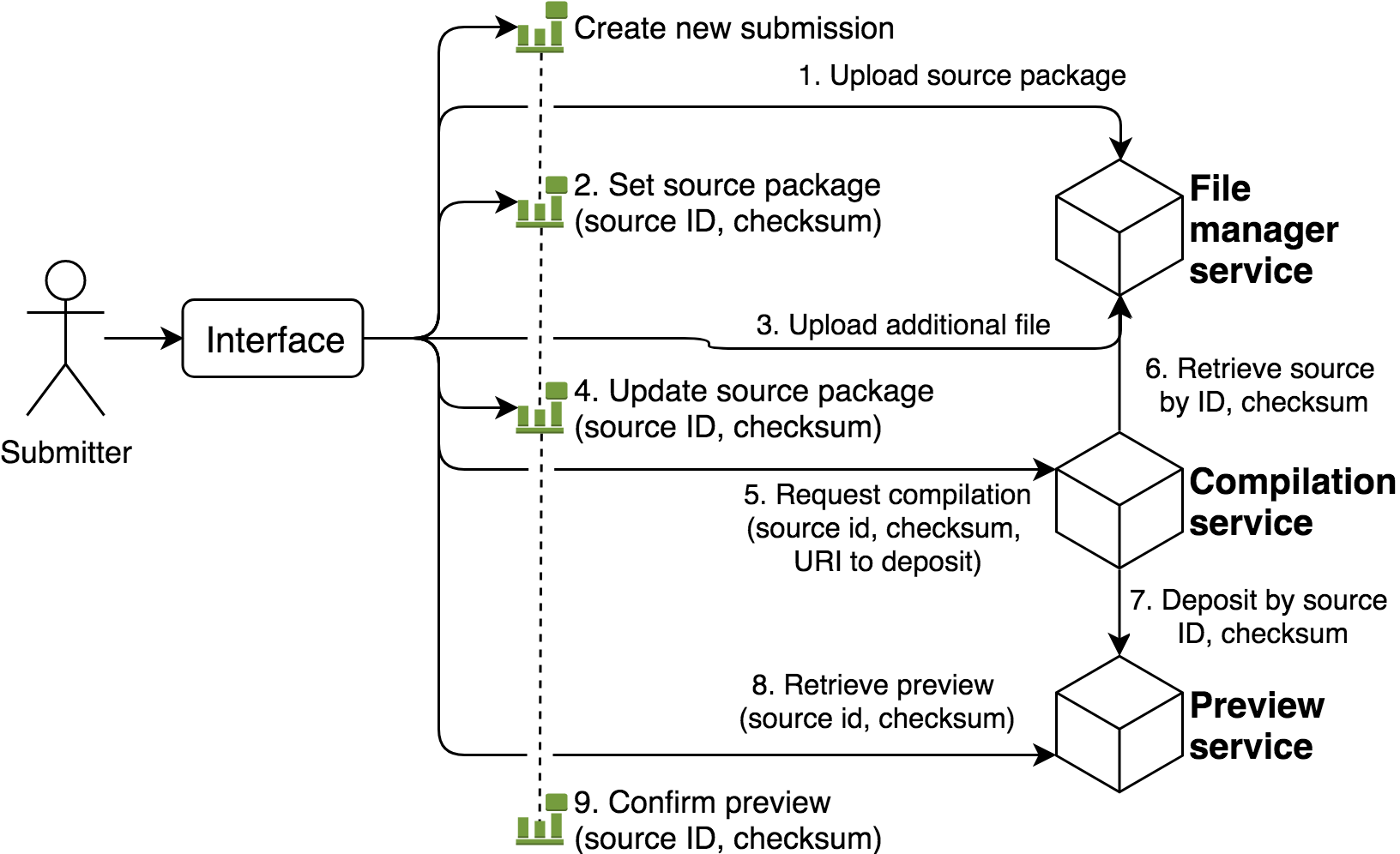
Fig. 16 Example of submission content workflow for a compiled format (e.g. TeX). The submission interface proxies the initial upload of the source package to the file manager service (1), and associates the source package with the submission (2). A subsequent upload is proxied to the file manager service resulting in a new checksum (3); the interface associates this new checksum with the submission (4). The submitter triggers processing via the interface, which requests compilation of a specific source ID and checksum, and requests that the result be deposited to the preview service (5). The compiler service uses the source ID and checksum to retrieve the correct source from the file manager service (6). The compilation service deposits the successfully processed preview to the preview service (7). The interface retrieves the preview to show the submitter (8), and then confirms the suitability of the preview as indicated by the submitter (9).¶
Moreover, the upload, processing (e.g. compilation), and preview requests need not be facilitated or proxied by an interface. The underlying services may be directly exposed to client requests via the API gateway. Note that an interface would still be required to generate the appropriate submission events to associate the source package and preview resources with the submission itself.
Typical workflow¶
Submitters (and external services) generate new submissions, which are comprised of metadata and a content object (e.g. a tar/gzipped TeX source bundle, or a single PDF file). Prior to consideration by moderators, submissions may undergo several rounds of modification. Submitters may revise metadata and/or upload revised content. During this process a handful of different services may need to operate on the submission. For example, the content is compiled into an arXiv PDF; links are extracted for consideration by the submitter; etc.
Upon submission, the paper may be subject to a variety of processing and moderation activities. Automatic classification algorithms may be run, which require pre-processing steps (e.g. plain text extraction). Moderators may propose re-classification, act on input from classification algorithms, make comments, etc. Depending on moderator activity, additional input from the submitter and/or administrators may be necessary.
Implementation: domains and services¶
This section deals with the implementation of the arXiv NG submission subsystem, focusing on the specific domains of the subsystem and services that implement the model elaborated above.
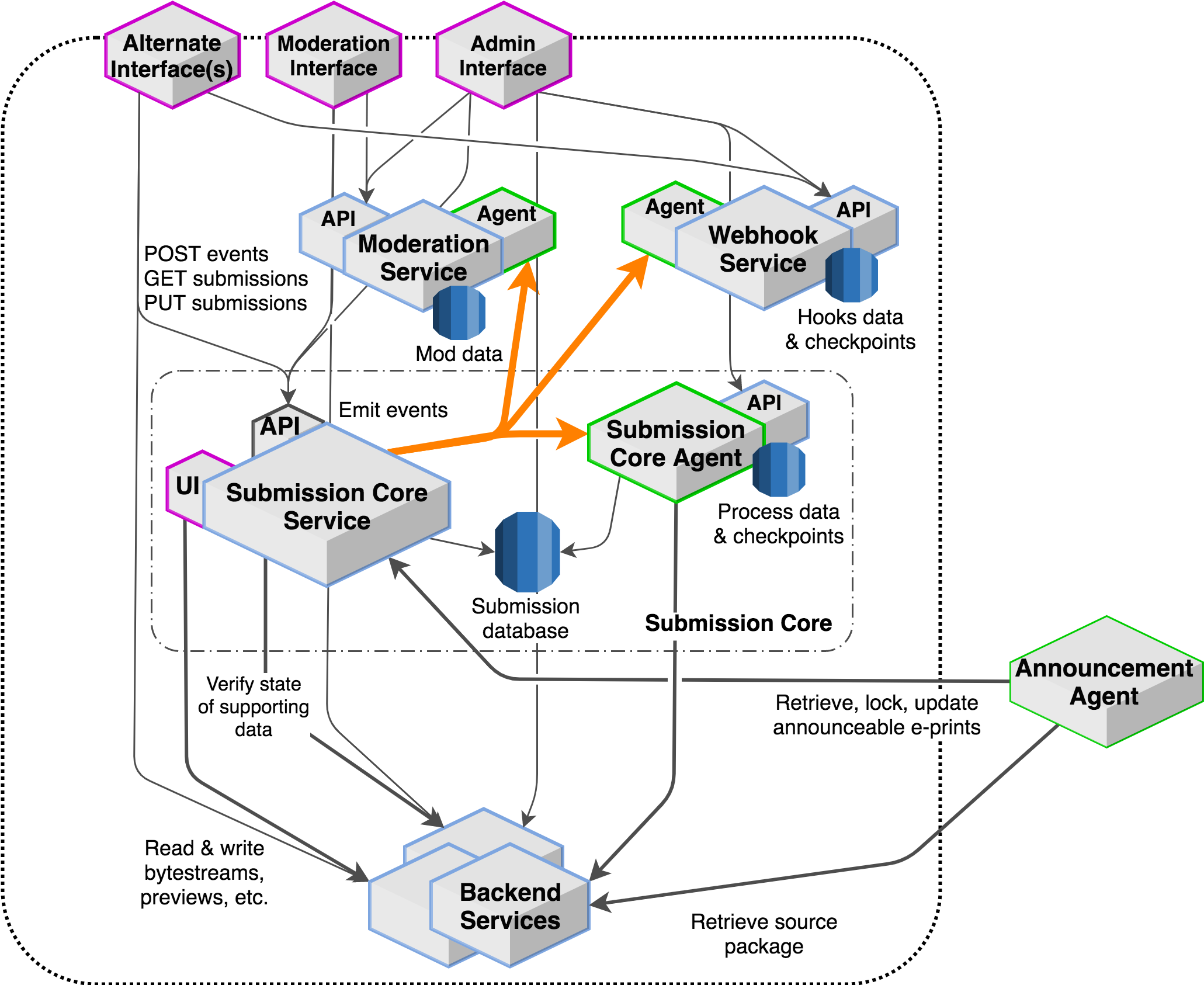
The submission subsystem is composed of a collection of more limited domains that address specific areas of concern. The two most significant domains are:
Accession of submission metadata and orchestration of the submission process, handled by the Submission service.
Moderation of submissions, including moderation queues, coordination and communication among moderators, etc, handled by the Moderation service and Moderation interface.
Human users will generally interact directly with these contexts, e.g. when using the submission and moderator user interfaces.
In addition, there are several more limited contexts that are composed to support submission and moderation activities. These include:
File upload & sanitization, handled by the File management service.
Compilation of LaTeX or Postscript source files to a PDF preview, handled by the Compilation service.
Availability of the submission preview, handled by the Submission preview service.
Extraction of plain text from the PDF preview, handled by the plaintext-service.
Detection of overlap based on plain text content, handled by the Overlap detection service.
Generation of classification suggestions, handled by the Classifier service.
Notification of API clients about events related to particular submissions, handled by the Webhook service.
Core submission domain¶
The core of the arXiv submission system is an event-driven data architecture that handles the descriptive and procedural metadata of the submission, and a set of interfaces and asynchronous processes that orchestrate and compose activities and resources in the other submission-related contexts.
Submission database¶
The submission database (currently MySQL) is responsible for the persistence of operational and core descriptive metadata about submissions. Operational metadata includes information related to arXiv workflows and processes. Core descriptive metadata are the core metadata fields required for arXiv submissions (e.g. title, authors, abstract). The primary source of truth for the state of each submission is a set of transformation events. Derivative representations (e.g. of submission objects) are also stored for querying and rapid access.
In early phases of the classic renewal process, this will be the classic MySQL database running in the CUL-IT datacenter. During the arXiv-NG project, submission data will be migrated to a standalone MariaDB or PostgresQL cluster in AWS RDS.
Submission core package¶
This package provides an event-based Python API for mutating submissions, and is the only mechanism for writing submission data to the Submission database. This package is used by both the API application itself and the Submission agent.
Provides a set of commands (events) that canonicalize operations on submissions, and are used as the basis for composing rule-based processing tasks for quality control.
Provides service integration modules for working with utility services (e.g. Utility services)
Provides integration with a notification broker (Kinesis) for disseminating events to other parts of the system (e.g. Submission agent).
Detailed package documentation can be found in arxiv.submission.
Submission service¶
The core submission service is a web application that provides both a form-driven user interface and a JSON REST API, backed by the Submission database.
With the exception of the Submission agent, all commands that mutate submission state are handled by this service. Moderation interfaces, the moderation agent, components of the announcement subsystem, and other services may query and alter submission state via the API provided by this service.
Submission agent¶
The submission agent orchestrates backend processes based on rules triggered by submission events.
The primary concerns of the agent are:
Orchestrating automated processes in support of submission and moderation.
Keeping track of what processes have been carried out on a submission, and the outcomes of those processes.
Providing a framework for defining conditions under which processes should be carried out.
Providing an API for administrative queries/monitoring of processes and their outcomes.
Sending e-mail notifications as needed in response to submission events.
The submission subsystem implements a wide range of quality assurance checks and other automated actions on submissions. Most of these checks are too unweildy to perform within the context of a submitter/client HTTP request. Moreover, in almost all cases it is important to guarantee that required checks and processes have taken place for all submissions; leaving this responsibility up to various submission interfaces would introduce unacceptable complexity and unpredictability.
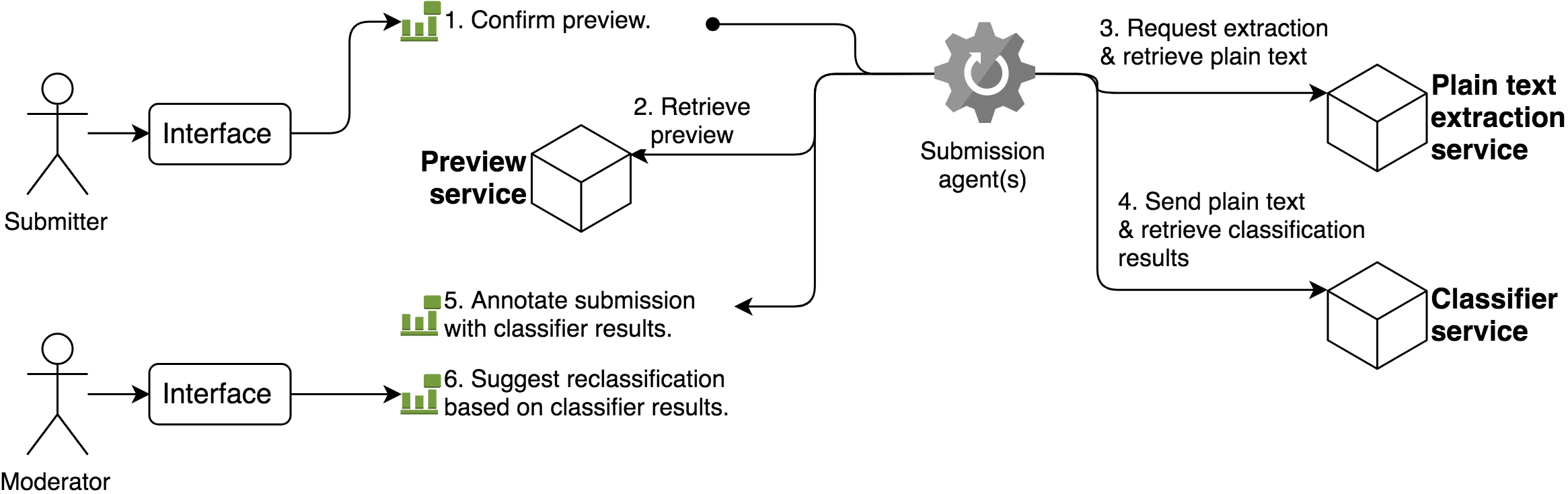
Fig. 18 Example of an automated process carried out by the submission agent. The submission agent consumes an submission preview confirmation event generated by a submission interface upon affirmation by the submitter (1). The submission agent applies rules that are configured by arXiv administrators, which indicate that a multi-step classification process should be carried out. This involves first retrieving the PDF preview (2), requesting plain text extraction from the PDF (3), requesting classification suggestions based on the plain text (4), and then annotating the submission (via an another event) with the classification results (5). A moderator may then use those results as the basis for a suggestion to reclassify a submission (6).¶
The submission agent is responsible for orchestrating quality assurance checks and other automated actions in response to submission events. It monitors all submission events generated by interfaces, and applies configurable rules and policies to those events to determine what actions (if any) must be performed. Processes are carried out asynchronously, and may generate additional submission events.
Examples of activities orchestrated by the submission agent include:
Enforcing size limits by applying flags and/or holds to submissions with oversize source packages.
Extracting plain text from submission previews, invoking the auto-classifier service to identify possible mis-classification, and using the results to generate proposals (as events) for reclassifying a submission.
Checking for possible textual overlap between submissions, to catch possible duplicates.
Note
It is not necessary for all policies and procedures to be implemented in just one such agent. As policies and processes for various arXiv classification domains evolve, for example, it may be desirable to introduce several such agents responsible for different domains. Many other divisions of concerns are conceivable, and at this time there is no limitation on or prescription for how agents are apportioned responsibilities.
The submission agent is supported by its own database, which is used for checkpointing progress in the SubmissionEvents event stream and tracking the outcome of its own processing steps.
In addition to a process that consumes the SubmissionEvents event stream, the agent also includes a web service that provides an API for administrative queries (e.g. to check the processes that have been run on a submission, and their outcomes).
Detailed documentation can be found at: TODO REPLACE ME
SubmissionEvents event stream¶
Events originating from the core submission domain (i.e. created by the
core submission service or agent) are propagated to other domains in the
submission subsystem via a SubmissionEvents stream. Each entry encodes a
single event, along with the state of the submisssion metadata prior to and
after the event occurred. Other agents in the submission subsystem may consume
events from this stream as required to implement domain-specific activities.
Note
Note that large bitstreams (e.g. PDF content) are not propagated via the event stream. Only the descriptive and procedural metadata for the submission (i.e. belonging to the core submission domain) are included in the event payload. Consumers may dereference source packages, PDFs, and other related content via the corresponding backend services.
The SubmissionEvents stream itself is currently provided by AWS Kinesis.
Future iterations of the NG system may leverage other pub/sub transports. Some
important characteristics of the transport are:
Unique identification of events in the stream.
Ordering of events.
Ability to replay events from a recent point in time, e.g. 24-72 hours.
(effectively) Unlimited number of consumers.
The SubmissionEvents stream is a good place for submission-related
applications that go beyond the current architecture to integrate with the
arXiv submission subsystem. Applications that are operated outside of the
arXiv infrastructure should integrate via the Webhook service and the
Submission service APIs.
Moderation domain¶
The moderation domain encompasses a wide range of moderation-specific concerns, including:
Configuration of moderation queues.
Scheduling of moderation activities (e.g. setting an “away” status).
Communication among moderators regarding submissions, e.g. moderator-specific commenting features.
Flags that are specific to moderation concerns, e.g. the ability to mark a submission as “seen” or “good to go.”
Configuration of rules and automated processes.
Moderation database¶
Moderation-specific state is persisted in a stand-alone database that backs the Moderation service.
Note
This database does not store core submission state, including any flags, holds, or annotations that belong to the Core submission domain.
Moderation service¶
The moderation service is a stand-alone application that supports moderation-specific concerns and activities. It provides a JSON REST API that supports the Moderation interface. Functionality supported by the API includes:
Configuration of the Moderation agent (e.g. creation, management of rules/automated processes).
Read/write moderation-specific comments and annotations.
Configuration of moderation queues.
Moderation agent¶
The moderation agent consumes submission events, and carries out programmatic moderation activities. In contrast to the submission agent, which implements arXiv-wide policy, the moderation agent supports more limited use-cases. For example, individual moderators can define rules for automated actions on their behalf.
Utility services¶
The following services provided specific functionality leveraged by the submission core and moderation domains.
File management service¶
https://github.com/arxiv/arxiv-filemanager
This service is responsible for ensuring the safety and suitability of files uploaded to the submission subsystem. The file management service accepts uploads, performs verification and sanitization, and makes the upload available for use by other services.
Compilation service¶
https://github.com/arxiv/arxiv-converter
The build service compiles sanitized upload packages into PDF, PostScript, and other formats. This service encompasses the arXiv TeX tree. Compilation logs are also made available, for example to provide submitters feedback about compilation failures or warnings.
Submission preview service¶
https://github.com/arxiv/arxiv-submission-preview
The submission preview service is a clearinghouse for PDF previews of submitted e-prints. Regardless of the original source format, the preview product must be deposited/can be found via this service. Previews are identified by the source ID and checksum of the corresponding source package in the file management service.
Plain text extraction service¶
https://github.com/arxiv/arxiv-fulltext
Extracts plain text content from PDFs, for use by the for overlap detection and classification services. Makes both raw extracted text and normalized “PSV” tokenized text available to other services.
Overlap detection service¶
https://github.com/arxiv/arxiv-docsim
Operates on extracted plain text content and submission metadata to detect possibly duplicate submissions. Returns an array of announced e-prints with a high degree of overlap.
Classifier service¶
https://github.com/arxiv/arxiv-classifier
Operates on extracted plain text content to propose categories for submitted papers.
Client-side interfaces¶
Moderation interface¶
The moderation interface is a client-side application implemented in React. In the classic system, the interface interacts with a “moderation API” backed by the legacy database.
In the NG system, the moderation interface interacts with both the core submission API (to query and effect interventions on submissions) as well as the moderation service (to read and write moderation-specific data).
Administrative interface¶
The administrative interface is a client-side application implemented in React. This interface leverages the APIs exposed by each of the services in the submission subsystem to provide a global view of submission and moderation activity, and tools to perform administrative actions.
Note
The scope of the administrative interface goes beyond the submission subsystem, with hooks into each of the other subsystems in the NG architecture.
Alternative interface(s)¶
It is envisioned that client-side interfaces provided by arXiv, or client- or server-side interfaces provided by trusted and authorized third parties, may also hook in to the submission subsystem via APIs to support submitter workflows.
Webhook notifications¶
API clients may register webhook URLs for specific submissions and/or events in the submission subsystem. The webhook service and agent (below) are backed by a standalone database in which the registered webhooks and related information are stored.
Webhook service¶
The webhook service provides a JSON REST API that supports adding, editing, deleting, and viewing registered webhooks. Clients may also access the history of a particular webhook, e.g. a log of requests issued by the Webhook agent to the webhook URL.
Webhook agent¶
The webhook agent consumes events in the SubmissionEvents event stream, cross-references those events with registered webhooks, and issues any consequent POST requests to those registered URLs.