One of the core functions that arXiv provides is long-term high-fidelity
storage of e-print announcements and attendant metadata. Ensuring the integrity
of that service is vital to maintaining trust within the scientific communities
that arXiv serves.
The arXiv canonical record is comprised of all of the announcement events and
e-print versions in the arXiv corpus, including their metadata, source content,
and canonical renderings.
This section describes the concepts, structure, and maintenance of the
canonical record.
The canonical record is the primary source of truth for e-prints
announced on the arXiv platform, and is comprised of both e-print metadata and
content including original submission content and derived PDFs.
Content is organized so that it can be easily determined what papers were
announced or altered on a given day.
At announcement time, the Announcement agent deposits new metadata
records, source files, and PDFs in the core repository. Changes to this
content can only occur through the announcement system.
The underlying storage technology must prioritize long-term durability.
Availability and response latency characteristics are less important, so long
as the daily announcement cycle is not significantly delayed (including
deposit of new metadata and updates to secondary data stores). Since
announcement is handled by a single process (and we do not expect that to
change), write performance is much less important than read performance.
The content of the canonical record is verifiable. A checksum is stored for
each object that is deposited in the repository that can later be used to
monitor content integrity.
It must be easy to backup, replicate, mirror, and share the arXiv canonical
record. This means that the system should have minimal dependencies (e.g. not
require obscure software to parse metadata records, not require access to
other data sources to interpret), and be conceptually as simple as possible.
The metadata record should be both human readable and readily parsed for
computational purposes.
Only publicly consumable information is allowed in the canonical record. This
minimizes the complexity of access control, and makes it simpler to provide
public APIs.
The following terms are used throughout this document. They are ordered
in a narrative fashion for the sake of readability for those unfamiliar with
the arXiv data model.
- Version
A scientific work comprised of a Source Package,
Canonical Render, and a Metadata Record.
- Source Package
The original content of a submission to arXiv provided by the
Submitter.
- Canonical Render
A representation of the scientific work suitable for consumption by
human readers. This is usually (but not always) a PDF compiled from TeX
sources in the Source Package at the time of announcement.
- Metadata Record
A collection of descriptive metadata associated with a scientific work.
It includes both the descriptive metadata provides by the
Submitter and also details about the Source Package and
Canonical Render. Note: this replaces the concept of the Abs
File in the Classic system. See Canonical metadata record.
- E-Print
An ordinal collection of Versions. The second and
subsequent Version are usually generated by replacement
or withdrawal Events. Each E-Print is assigned
a unique arXiv Identifier at the time of announcement of its
first Version.
- Event
An announcement-related activity that results in the creation or
modification of a Version. See Event types.
- Listing
A record containing a subset of Events.
- Event Stream
The chronological series of all Event in the
Canonical Record.
- Submitter
The human user responsible for transmitting a scientific work to arXiv.
This may or may not be an author of the work.
- Client
The system that mediated the transmission of a scientific work to
arXiv.
- Canonical Record
The entire collection of Events and Versions in the arXiv system.
- Primary Record
The authoritative copy of the Canonical Record. This is the
source of truth for all other records and systems. See
Primary announcement record.
- Announcement Agent
The software system that maintains the Primary Record, and
writes the Event Stream. See Announcement agent.
- Replica
A non-authoritative copy of the Primary Record. A Replica may
be Partial (i.e. containing only a subset of Events and
Versions) or Complete.
- Observer
A system that processes an Event Stream.
- Replicant
An Observer that generates and maintains a Replica.
- Repository
A server that provides access to the current state of the
Canonical Record to other systems.
- Announcement
The creation or modification of a Version, usually based on a
submission.
- Announcement Date
The date on which a Version was Announced.
- Original Announcement Date
The date on which the first Version of an E-Print was
Announced.
- Fixity Checksum
The URL-safe Base64-encoded MD5 digest of bytes content. The content
may be the raw content of a file.
- Manifest
A record of resources and Fixity Checksums in
a part of the Canonical Record.
- arXiv Identifier
A unique identifier assigned to an E-Print on the day that its
first Version is Announced. See
arxiv-identifier.
- Versioned Identifier
An arXiv Identifier with a version affix, e.g. v5, that
refers to a specific Version. See arxiv-identifier.
Each resource in the Canonical Record is stored as a bitstream value in
a key-value store.
The key prefix structure for a Version record is:
e-prints/<YYYY>/<MM>/<arXiv ID>/v<version>/
Where YYYY is the year and MM the month during which the first
Version of the E-Print was announced.
Sub-keys are:
Metadata record: <arXiv ID>v<version>.json
Source package: <arXiv ID>v<version>.tar.gz
PDF: <arXiv ID>v<version>.pdf
The purpose of this record is to provide the ultimate source of truth regarding
a particular E-Print and its Versions.
Events are stored in Listing files. The key prefix
structure for Listing file is:
announcement/<YYYY>/<MM>/<DD>/
YYYY is the year, MM the month, and DD the day on which the
Events encoded therein occurred and on which the subordinate
Listing files were generated.
Each daily key prefix may contain one or more sub-keys. Each sub-key ending in
.json is treated as a Listing file.
In order to efficiently verify the completeness and integrity of a
Replica, and to identify the source of inconsistencies, consistency
checks are performed at several levels of granularity. The completeness and
integrity of all or a part of the Canonical Record can be verified by
comparing the checksum values at the corresponding level of granularity. The
way in which checksum values are calculated for each level is described below.
This is inspired by the strategy for checksum validation of large chunked
uploads to AWS S3. All checksum values are md5 hashes, stored and
transmitted as URL-safe base64-encoded strings.
Completeness and fixity can be verified at each level as follows:
Level |
Completeness |
Integrity |
|---|
File |
Presence/absence of a key
in key-value store. |
Hash of the content bitstream. |
Version |
Number and names of files. |
Hash of the concatenated (ordered
lexicographically by name of the
content file) file integrity
hashes. |
E-print |
Number of versions. |
Hash of the concatenated version
integrity hashes, sorted by
ascending version number. |
Day |
Presence of all e-print keys. |
Hash of the concatenated e-print
integrity hashes, sorted
lexicographically by identifier. |
Month |
Presence of keys for all calendar
days in the month. |
Hash of the concatenated day
integrity hashes, sorted
chronologically. |
Year |
Presence of keys for all calendar
months in the year. |
Hash of the concatenated month
integrity hashes, sorted
chronologically. |
All |
Presence of keys for all years
since 1991. |
Hash of the concatenated year
integrity hashes, sorted
chronologically. |
The keys of members and each of their calculated checksums are recorded in
Manifest records. These manifests are considered to be outside of the
canonical record itself, so their integrity should be ensured independently.
Manifest records are maintained at each level of the Canonical Record.
Each record contains a mapping of member keys to integrity checksums. For
example, a manifest record for a particular year would contain a mapping like:
{
"2021-01": "[ fixity checksum for 2021-01 ]",
"2021-02": "[ fixity checksum for 2021-02 ]",
"2021-03": "[ fixity checksum for 2021-03 ]",
"2021-04": "[ fixity checksum for 2021-04 ]",
"2021-05": "[ fixity checksum for 2021-05 ]",
"2021-06": "[ fixity checksum for 2021-06 ]",
"2021-07": "[ fixity checksum for 2021-07 ]",
"2021-08": "[ fixity checksum for 2021-08 ]",
"2021-09": "[ fixity checksum for 2021-09 ]",
"2021-10": "[ fixity checksum for 2021-10 ]",
"2021-11": "[ fixity checksum for 2021-11 ]",
"2021-12": "[ fixity checksum for 2021-12 ]"
}
The preservation record is a daily digest containing the
Versions and Events for that day. The purpose
of the preservation record is to facilitate long-term archiving of arXiv
content in cases where direct replication of the canonical record is unwanted
or impractical. For example, many long-term dark archive service providers
ingest content and transform it into a normalized format.
The key structure of the daily preservation record is:
announcement/<listing>.json # Events for the day.
e-prints/<arXiv ID>v<version>/
<arXiv ID>v<version>.json # Metadata Record
<arXiv ID>v<version>.tar.gz # Source Package
<arXiv ID>v<version>.pdf # Canonical Render.
<arXiv ID>v<version>.manifest.json # Version Manifest.
suppress/<arXiv ID>v<version>/tombstone
preservation.manifest.json
The preservation.manifest.json record is similar to the version manifest
record; it contains all of the keys and corresponding checksums for the items
in the preservation record.
The suppress/ key prefix is used to indicate Versions
the contents of which (for legal reasons) have been removed from the
Canonical Record and should be suppressed from dissemination in the
event that the archive is “lit up” for public consumption. The tombstone
record is an UTF-8 encoded plain text file containing a brief account of
the reason for suppression.
The following types of Event are supported. The “Δ Content” column
indicates whether or not the Event results in modification or addition
of content. All events result in changes to E-Print metadata via
modification or creation of a Metadata Record for a Version.
Event type |
Description |
Δ Content |
|---|
new |
Creation of the first Version of an
E-Print. |
Yes |
update |
Changes to an existing Version. |
Yes |
update_metadata |
Changes to the metadata of an existing
Version. |
No |
replace |
Creation of the second or subsequent
Version of an E-Print. |
Yes |
cross |
Addition of secondary classification terms to an
existing Version. |
No |
jref |
Modification of the DOI, journal reference, and/or
report number metadata fields. Deprecated. |
No |
withdraw |
Creation of a new Version of an
E-Print that declares the E-Print
to be withdrawn. This Version has no
associated content. |
Yes |
migrate |
A change to the structure or format of a
Version. For example, adoption of a new
encoding, or addition of a new bitstream. |
Yes |
migrate_metadata |
A change to the structure or format of the
metadata of a Version. For example,
addition of a new core metadata field. |
No |
At the end of the daily announcement process, the announcement agent shall
generate an announcement_complete event on the Event Stream.
This event contains a summary of the announcements for that day.
This section describes how the Canonical Record is updated and
replicated.
This section describes how a new Replicant shall come up to date if it
falls behind in processing Events from the
Event Stream.
Each Event is assigned a monotonically incrementing integer value,
starting at 0 on each announcement day. The Events for each
announcement day, as well as the years, months, and days on which
Events were generated may be retrieved via the
Repository for the Primary Record.
The Replicant shall connect to and retrieve the first Event in
the Event Stream. It shall then call the Repository for the
Primary Record to retrieve and process all Events prior
to the loaded one, in chronological order.
During catch-up, the Replicant shall update its local fixity
Manifests, but shall not verify checksums until all prior
events are processed.
Once all prior Events are processed, the Replicant
shall process the initially loaded Event and proceed with replication
as normal.
Other Observers may use a similar approach if catch-up is
required.
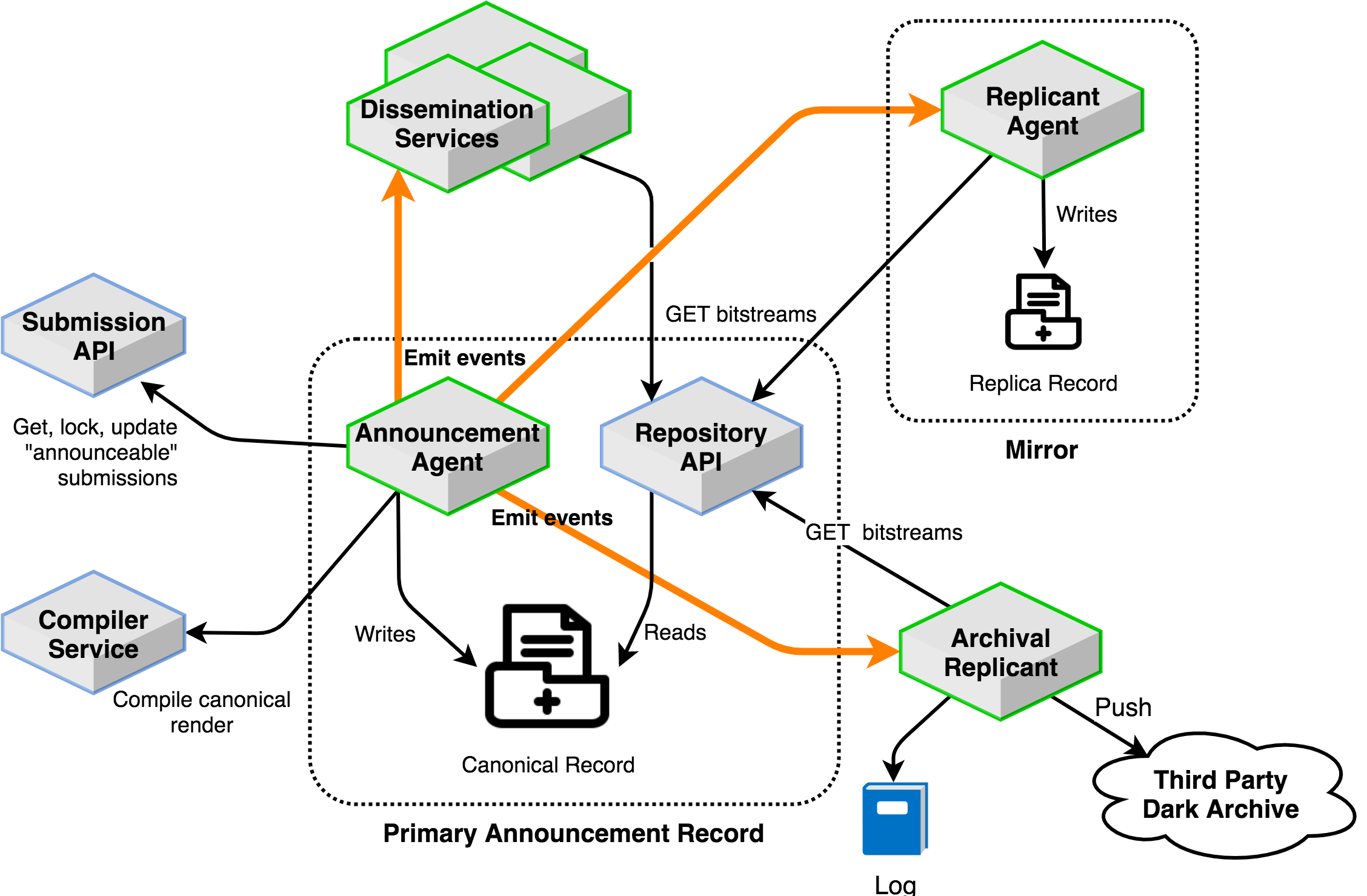
This section describes the domains within the announcement system, and the
services that implement and maintain the canonical record.
https://github.com/arXiv/arxiv-canonical
The Primary Record is the authoritative source of truth about the
Canonical Record. It is comprised of the canonical record data itself, an Announcement agent that
operates the daily announcement process and updates the record with data from
the submission subsystem, and a Primary repository that provides a
read-only API for the canonical record (including Source Package
and Canonical Render) to other services.
The primary canonical record is stored in AWS Simple Storage System (S3), which
provides a RESTful HTTP API for setting and getting binary content based on
simple keys. Access to the canonical record bucket is strictly limited to the
Announcement agent and the Primary repository.
Listings and Metadata Records
are serialized in JSON, and stored as UTF-8 encoded text files. JSON Schema
documents are used to describe and validate the metadata records, and are
stored in https://github.com/arXiv/arxiv-canonical.
The announcement agent is a periodic process that runs in a single thread once
per day. The announcement agent is responsible for:
Getting publishable E-Prints from the submission system,
and marking them as Announced.
Minting new arXiv Identifiers.
Writing to the Primary announcement record.
Populating the Event Stream with information about each
Event in order to facilitate downstream work by other
agents/services (e.g. to update the search index, generate announcement
emails).
The primary Repository is a small web service that provides a RESTful
JSON API for resources in the Primary Record. Operations supported by
this API include:
This API is used by other services in the arXiv NG system, as well as external
clients, to access the canonical record.
Note
It will be strongly preferable to include a backend cache in the
implementation of the repository software, as requests for particular
resources or sets of resources in a given period of time are likely to
be biased toward a small subset of all resources.
Historically, member institutions have operated a global network of mirror
sites, but many mirrors have become unavailable over time due to lack of
maintenance and aging technology. In late 2015, the decision was made to begin
dismantling the mirror network as trying to maintain them presented an
impediment for developing new features on arΧiv.
Currently, only four of the original thirteen mirrors remain open and are
updated daily. Yet many of the drivers that motivated the existence of the
mirrors in the first place—such as resilience to sustained outages and
geopolitical redundancy—continue to exist.
This section describes the implementation of arXiv NG mirrors as
Replicants in the canonical record framework.
The mirror Replicant in an agent process that consumes the Event
Stream via the Replication protocol described above. Like all
other NG applications, it runs as a standalone Docker container that can be
deployed on any infrastructure.
As mentioned above, the backing storage system must support storage and
retrieval of binary content by key. The software for the canonical record
supports both local filesysystem and S3 storage backends.
The mirror can provide the public arXiv site by deploying the browse
application, which leverages the Mirror repository API.
The archival Replicant is responsible for assembling and distributing
the daily Preservation record. Like the Mirror replicant-agent,
the archival replicant processes the Event Stream in real time. Rather
than writing the Events in the canonical format, however, it
adds records (dereferencing and downloading bitstreams from the
Primary repository as needed) to the daily preservation record.
The record closes at midnight ET, at which time the preservation record is
pushed to third-party archives for processing. The archival replicant maintains
a log of interactions with third-party systems.