Dissemination Subsystem¶
Overview¶
This area of concern encompasses access to and discovery of arXiv content, both for human readers and API consumers.
The daily cycle of announcement decouples events in the submission system from the availability of new announcements in the main public-facing parts of the arXiv.org website. This allows us to separate the data stores that support access, discovery, and presentation aspects of the system from the core metadata and content repositories. This in turn allows for better horizontal scaling of the most heavily used parts of the system, and more efficient data representations to support different kinds of access patterns, without putting excessive strain on the primary data stores.
Key Requirements¶
Consistent presentation of e-print metadata, source packages, and PDFs;
Generation notifications for humans (via e-mail) and API consumers (via HTTP requests) about new e-prints;
Supplementary metadata, provided by authors and external data sources, are used to enhance e-print metadata and provide valuable links to related scholarly objects.
Modern performant search system (user interface and API) that provides highly relevant results based on metadata and full-text content.
Overall high availability/responsiveness to user/consumer requests; should be highly resistant to latency or downtime in other parts of the system.
Support future development of supplemental data services, e.g. citation networks, co-author networks, suggestions based on reader preferences/behavior, etc.
Strategy overview¶
The submission and moderation system implements the generic architecture described in Building blocks.
Announcement notifications generated by the Announcement agent trigger a variety of post-announcement activities coordinated by agents. For example, updating the search index, extracting plain text content for TDM, etc.
Services in the dissemination subsystem rely on secondary data stores tailored to intended access patterns. For example, the search system is backed by ElasticSearch, which supports rapid retrieval of relevant e-prints based on their metadata and full text content.
In some cases, services need not maintain their own secondary data stores. For example, the RSS feed service may leverage the existing search index via the search API.
Context¶
Readers search for, browse, discover, and retrieve arXiv e-prints and their metadata. Readers may subscribe to arXiv by registering their e-mail notification preferences.
API consumers access arXiv content programmatically via APIs proxied by the API Gateway. API consumes may register webhooks so that they will receive notifications about new e-prints via HTTP request.
Administrative functionality is provided by each service via API, to support integration of client-side administrative UIs.
Domains & Services¶
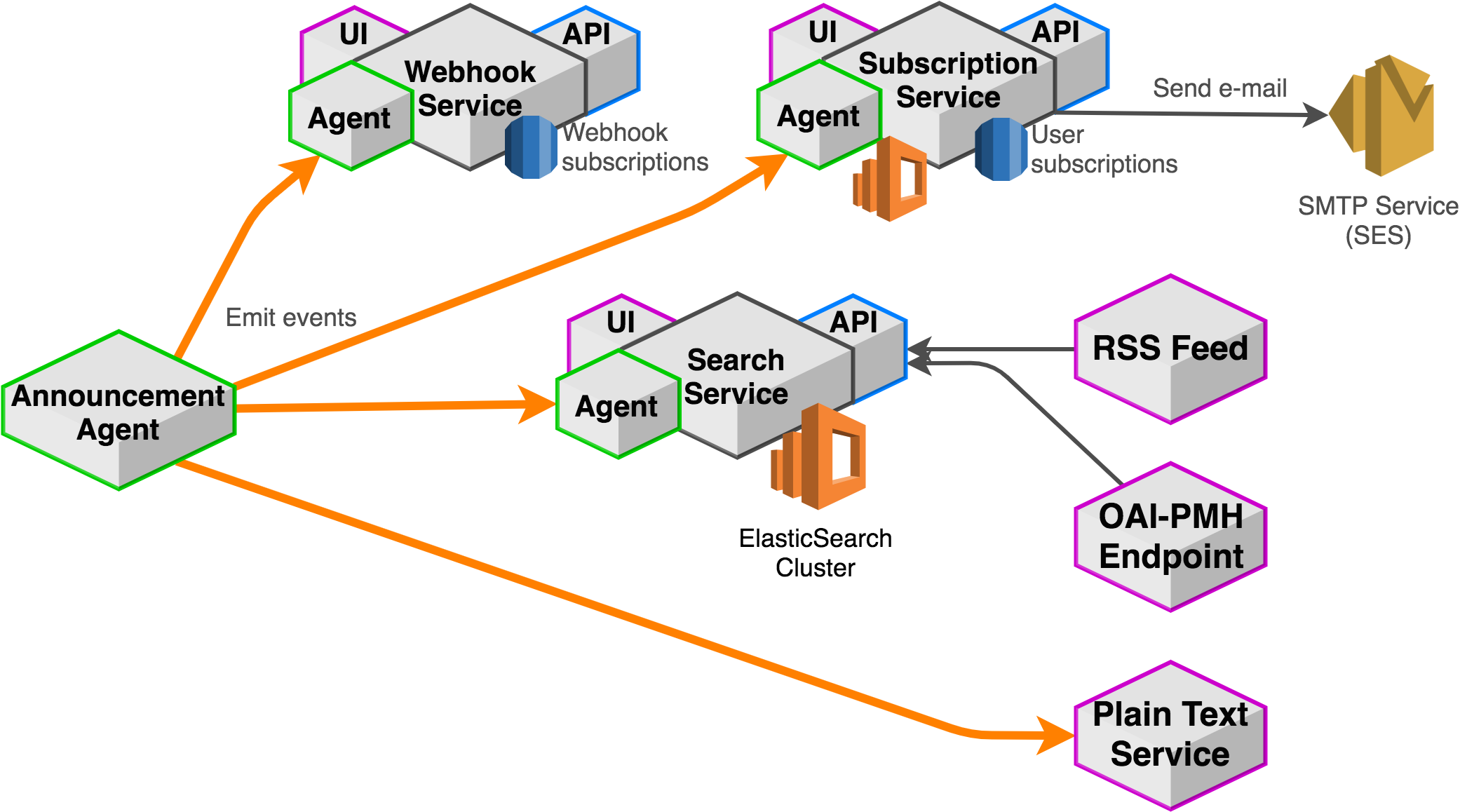
Fig. 20 Overview of dissemination services.¶
Browse service¶
https://github.com/arxiv/arxiv-browse
Provides the primary user interface for browsing arXiv e-prints. Readers may browse announcement information by category and time period, and retrieve version metadata (the “abs page”), source content, and renders. Relies on a Repository service to retrieve metadata and content from the Canonical Record.
Subscription service¶
The subscription service is responsible for updating arXiv readers about updates to the canonical record. This includes announcement of new e-prints as well as changes to existing e-prints. This service provides user interfaces to control e-mail subscriptions. Users may specify their subscription preferences as a fielded query (similar to search), and receive announcements as a daily digest or on a continuous basis.
Implementation guidance:
The service should be backed by a small Elasticsearch cluster that uses a document mapping similar to the one used by the search service.
Use the metadata included in announcement events to populate a separate index for each announcement day.
After the daily announcement cycle (upon receipt of the Announcement completion event) the service should query the index for that day using each of the subscription queries, and generate e-mails as appropriate.
Search service¶
https://github.com/arxiv/arxiv-search
Provides user interfaces for basic, advanced, and faceted search, as well as special result pages (e.g. for author authority records, ORCIDs, etc).
Backed by an high-availability Elasticsearch cluster.
An indexing agent consumes notifications about the availability of metadata for new or updated e-prints, retrieves the content, and updates the search index accordingly.
Provides external APIs for programmatic queries of published arXiv content. Used to back other external APIs, e.g. the RSS/Atom feed.
_webhook-notifications-dissemination:
Webhook notification¶
A webhook service provides a JSON REST API for API consumers to register URLs that should receive POST requests upon certain announcement events.
Note that the same software may be used for both this deployment and for the Webhook notifications in the submission system, configured to read from the canonical announcement Event Stream rather than the SubmissionEvents event stream.
Plain text extraction service¶
https://github.com/arxiv/arxiv-fulltext
This service provides backend and external APIs to request plain text extracted from e-print PDFs.
The plain text exectraction agent consumes the Event Stream and looks for events that generate new PDFs. It retrieves PDFs from the :ref`primary-repository`.
Note that the same software may be used for both this deployment and for the Plain text extraction service in the submission system, configured to read from the canonical announcement Event Stream.
OAI-PMH service¶
Provides an external API for retrieving arXiv metadata that is compliant with the Open Archives Initiative Protocol for Metadata Harvesting.
May be backed by the Search service API.
RSS/Atom feed¶
https://github.com/arxiv/arxiv-rss
Provides an external RSS/Atom endpoint for API consumers. Backed by the Search service API.