Backup & Recovery¶
Protecting arXiv data from loss is a critical priority of the arXiv-NG project. The arXiv system stores data in a variety of forms and facilities. In Data architecture: integrity and flexibility it was noted that the durability expectations of those data can vary considerably. This chapter describes the risk model for various kinds of data in the arXiv system, the backup strategy and infrastructure for those various data, and the model for recovery planning that is applied to each data storage facility.
Scope & duration¶
This backup and recovery plan is intended to guide data protection and risk management over the next 25 years. Given the extended scope of this document, it is fully anticipated that this plan will be updated over time as technologies and risks evolve. This long-term perspective, however, helps us to calibrate our understanding of the impact of risk beyond short-term SLAs.
Storage & backup tiers¶
Depending on the criticality of a dataset, the backup and recovery plan for the responsible data store may involve one or several tiers:
The data store itself, e.g. a network file system, or the AWS S3 service.
Platform backups, e.g. disk snapshots, S3 versioning, database dumps. These backups should be closely in-sync with the data store, and provide mechanisms for rapid restoration when the primary data store fails.
Alt-site backups. These backups provide platform-independent redundancy. For on-premises data stores this may be a cloud-based backup, and vice versa. These backups protect against more catastrophic failures, and likely involve a longer recovery timeline.
Long-term archives and mirrors. These backups provide insurance against catastrophic failure of the arXiv organization. While these facilities may provide a recovery path in the worst case scenario, their primary purpose is to preserve the scientific record if arXiv were to permanently cease to exist.
Criticality¶
We use four ranks to describe the criticality of a specific type of data in a specific data storage facility.
Highest. These data are essential to the core mission of arXiv, and cannot be re-created if lost. Losing these data would substantially undermine arXiv’s ability to achieve its mission. An example of highest criticality data is the core metadata record for each announced paper.
High. These data are operationally highly valuable, and cannot be recreated if lost, but their loss would not fundamentally challenge the integrity of arXiv as a whole. This includes user-generated data, such as submission data for papers that have not yet been announced.
Moderate. These data are not critical to arXiv’s core mission, but cannot easily be re-created. For example, author-curated links.
Low. These data can easily be re-created, albeit with some interruption of specific services. For example, the search index, which can be rebuilt from paper metadata records.
We assign each of these ranks an acceptable probability of data loss. This is the number of instances of data that loss is acceptable over the entire 25-year period.
Criticality |
Acceptable loss over 25 years |
|---|---|
Highest |
1e-6 (one in a million chance that a record will be lost) |
High |
1e-3 |
Moderate |
100 |
Low |
1e3 |
Risk model¶
We estimate expected data loss based on the SLAs of the data store and redundant backup solutions, our views about the reliability of the companies that provide those solutions, and our views about the risk of data being compromised due to failures not encompassed by solution SLAs.
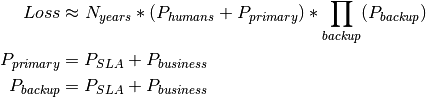
Human causes of loss¶
We assume that humans are the largest source of risk for data loss. This includes operational and programming errors by the arXiv team, as well as risk from malicious actors (e.g. ransomware, bitcoin miners).
We refer to Klahr et al 2017 1, based on survey data from UK companies, to estimate the risk from malicious actors. arXiv has the advantage of not holding sensitive user data (such as financial records). Nevertheless, we consider the observed rate of a cyber security breaches for professional, scientific, and technical organizations of 60% in 2017 to be a reasonable estimate of risk for arXiv. The same survey indicated that 7% of breaches resulted in the permanent loss of files. This suggests that the risk of losing some amount of data due to a malicious actor is around 4.2% per year.
Estimates of data loss due to non-malicious human error vary widely. We assume that the risk of losing some data due to human error is a comparable to the risk due to a malicious actor, putting the total risk of some data loss due to human causes at around 8.4% per year.
Risk of platform/business failure¶
We assume that there is a non-negligible risk of a data store becoming unavailable due to a business decision or failure. While we would hope that such a scenario would involve a controlled exit path for customers, we cannot take that for granted. We assume that the risk of data loss due to a business failure is comparable to the durability SLA that the business guarantees.
Number of objects per year¶
The number of data objects that are held in a given year will vary among data stores, but will be related to the number of e-print versions held in arXiv. Based on data from the past several years, we expect arXiv to grow at a rate of about 10% per year for the foreseeable future.
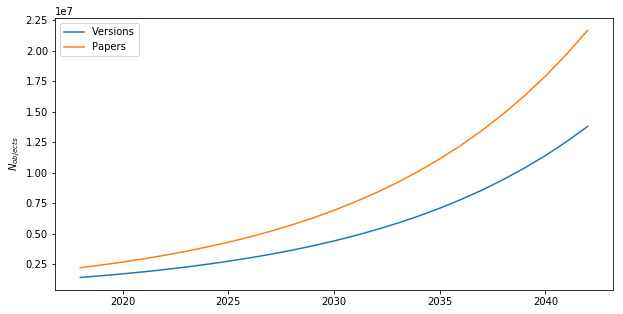
Fig. 25 Projected size of the arXiv corpus over the next 25 years.¶
The total number of object-years for papers is expected to be around
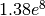 , and for versions around
, and for versions around 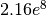 .
.
Example: Highest criticality data in AWS S3¶
The durability SLA for AWS S3 is 99.999999999%, meaning that the risk of each object being lost in a given year is 1e-11. Assuming that our critical data consists of two objects per paper version, we calculate the probability of loss over the next 25 years due to the S3 SLA and risk of business failure as:
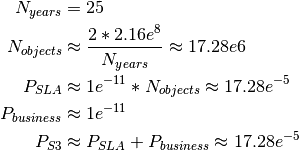
The S3 SLA does not include platform backups due to versioning, which has a similar SLA.
The total expected loss with S3 and S3 versioning is therefore:
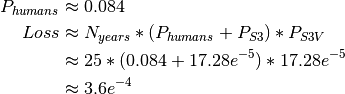
This falls short of the acceptable loss for highest criticality data
(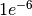 ), suggesting that an additional backup solution with a SLA
that guarantees
), suggesting that an additional backup solution with a SLA
that guarantees 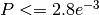 is necessary.
is necessary.
Storage platforms¶
The arXiv system relies on data stored in the following facilities/platforms.
MySQL Server (on-premises)¶
The classic arXiv system relies on dedicated MySQL servers provided by CIT. CIT does not provide a durability SLA for MySQL.
CIT performs nightly snapshots of the SQL database, which are replicated to off-site tape backup, provide a strong platform backup mechanism. In addition, we replicate data across three MySQL servers in real time. We make snapshots from the replica every two hours with a rolling window of approximately 2 days.
AWS Relational Database Service (RDS)¶
We will increasingly rely on RDS to back specific components of the arXiv-NG system. AWS does not publish a durability SLA for RDS. However, RDS is backed by EBS (below), which can serve as a best-case figure for un-replicated RDS instances. RDS can be deployed in a multi-AZ replication configuration, increasing durability.
In contrast to the legacy system which is backed by a single large database, arXiv-NG components will rely on a larger number of independent databases. Provisioning separate RDS clusters to back those components can further increase durability.
AWS provides RDS snapshots, which serve as a platform backup mechanism.
AWS Simple Storage Service (S3)¶
We currently use S3 to replicate announcement data stored on SFS for an independent failover in the case that the on-premises web services become unavailable. Going forward, we will use S3 as the primary data store for Announcement content and metadata.
The durability SLA for AWS S3 is 99.999999999%, meaning that the risk of each
object being lost in a given year is 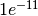 .
.
In addition, S3 object versioning acts as a platform backup mechanism with a similar durability SLA.
AWS Elastic Block Store (EBS)¶
We use EBS for network disk storage backing deployments on our Kubernetes cluster. For example, the Elasticsearch and Logstash clusters that we use to house access and application logs are backed by EBS volumes (one volume per pod).
EBS volumes have an annual failure rate of 0.1% to 0.2%. Each EBS volume is deployed in a single availability zone; cross-zone replication can be achieved either by spreading EBS-backed pods across multiple zones, or by replicating backups across zones.
AWS offers EBS snapshots as a platform backup mechanism.
See the AWS EBS documentation <https://aws.amazon.com/ebs/details/> for details.
AWS Kinesis¶
We use Kinesis to propagate short-lived notifications among arXiv-NG components. AWS does not publish an explicit durability SLA, except to specify that data are only expected to persist for up to 24 hours. Components that rely on Kinesis should be tolerant to the possibility of failed message delivery, however slight. Where missed messages are not acceptable, a mechanism should exist to audit the component for possible missed messages.
Backup & recovery plan model¶
The documentation for each data store in the arXiv system should include a backup and recovery plan. The plan must address the following topics:
What is the criticality of the data?
What storage platform is used, and what platform backup mechanism(s) are in place?
What redundancy/replication characteristics are in place, either in the design/deployment of the service or in the configuration of the storage platform?
What additional backup solutions (e.g. alt-site backups, dark archives) are in place? What mechanisms are used to update those backups and guarantee consistency?
What are the possible loss scenarios for the data? This should address vectors for:
Loss from human or programming errors.
Failure of the primary storage facility.
Failure of the platform backup.
For each of those scenarios, what protections are in place to reduce the risk of their occurrence?
For each of those scenarios, what is the step-by-step procedure for recovering from that failure? What is the estimated timeframe for a full recovery?
Documentation of past data loss or corruption, including a summary of the causes, impact, recovery process, and any long-term outcomes (e.g. unrecoverable data, software fixes, changes to dev/ops processes).
- 1
Rebecca Klahr, Jayesh Navin Shah, Paul Sheriffs, Tom Rossington, Gemma Pestell, Mark Button, and Victoria Wang. April, 2017. Cyber security breaches survey 2017. https://assets.publishing.service.gov.uk/government/uploads/system/uploads/attachment_data/file/609186/Cyber_Security_Breaches_Survey_2017_main_report_PUBLIC.pdf