Deployment infrastructure¶
This section describes the core infrastructure of the arXiv-NG system, focusing on how we deploy and run services and on shared system-wide resources.
Orchestration with Kubernetes¶
To the greatest extent possible, arXiv-NG services should be agnostic about the underlying servers that house them. To achieve this decoupling between server infrastructure and service deployment, we use Docker and Kubernetes. Docker encapsulates application runtimes, so that we can run our services on any platform that supports Docker. Kubernetes provides a layer of abstraction on top of the servers and network infrastructure, allowing us to spend more time reasoning about services and deployments rather than the servers that support them.
arXiv-NG applications run within a Kubernetes cluster spanning
multiple availability zones in the us-east-1 (Virginia) region. Kubernetes
maintains and scales a pool EC2 instances onto which NG applications (as Docker
images) are deployed.
Kubernetes cluster¶
Our Kubernetes cluster is provisioned and managed using kops. kops is responsible for setting up the VPC and subnets into which Kubernetes is deployed, setting up security groups, and provisioning and configuring EC2 resources for the cluster.
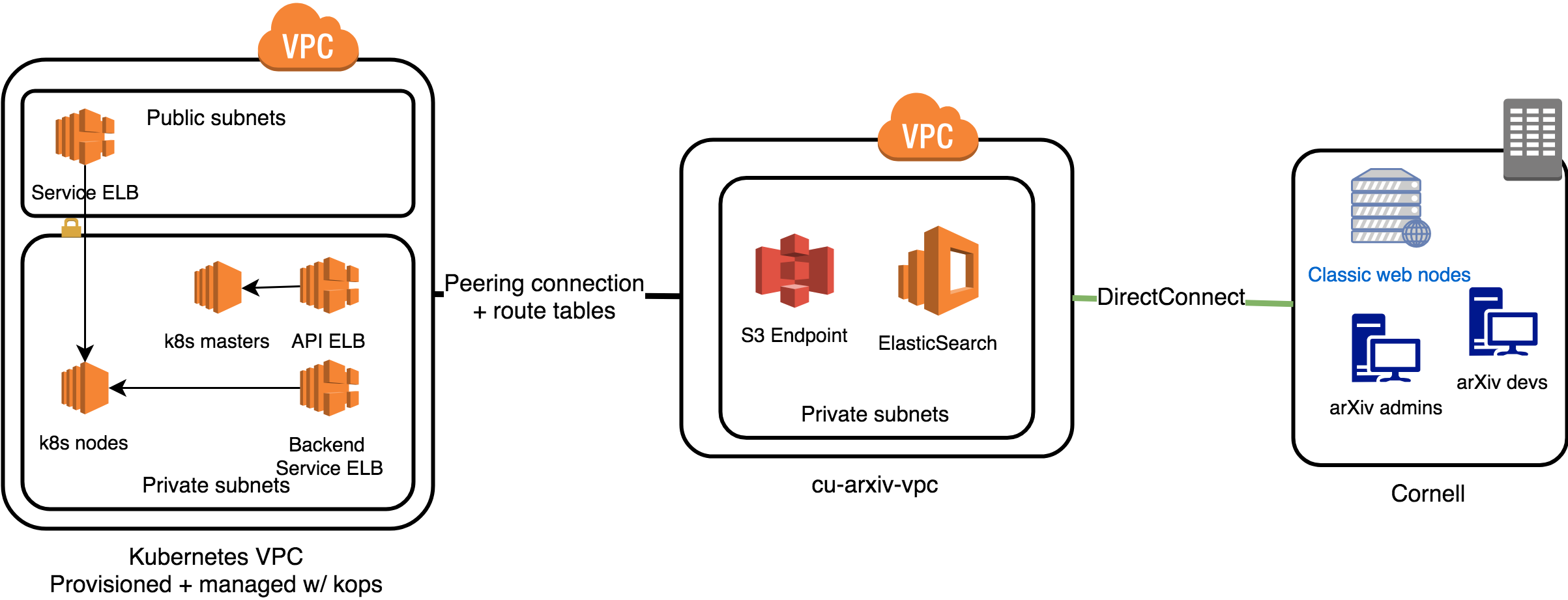
Fig. 22 Network layout for arXiv-NG, including both cloud-based and on-premises components.¶
Regions & zones¶
Currently we are deployed in the us-east- zone, with nodes and masters
spread evenly across its three regions: us-east-1a, -1b, and 1c.
As we go forward, we will explore options for a multi-region deployment.
Private network topology¶
This means that masters and nodes are deployed into private subnets within the VPC. Access to the masters (which provide the Kubernetes API) is controlled by a security group managed by kops. Access can be granted to additional API clients by adding CIDRs to the kops configuration.
EC2 instance size¶
We are currently using t2.micro instances for masters, since they are
lightly and sporadically used (mainly for deploying software).
We use a mix of t2.medium and t2.2xlarge instances for nodes, which are
running the actual applications in the cluster. This is likely to change as our
understanding of resource requirements and performance characteristics evolve.
Networking¶
Kubernetes maintains its own internal DNS
for routing requests to services within the cluster. We use the
kopeio-vxlan networking provider, which was purpose-built for Kubernetes,
fully integrates with the Kubernetes API, and is therefore much simpler to
use than the alternatives. We would have used the kube-router provider,
but at this time it does not play well with the private network topology.
Integration with on-premises infrastructure¶
The one component of our network infrastructure that is manually configured is the connection between the Kubernetes cluster and our on-premises resources.
CUL provides a DirectConnect gateway that connects our on-premises servers and
VPN-connected clients to the cu-arxiv VPC in AWS.
Some AWS resources (e.g. ElasticSearch service, S3 endpoints, etc) must be
accessible by both on-premises machines and by machines in the Kubernetes
cluster. To achieve this, we use a Peering Connection between the Kubernetes
VPC (provisioned by kops) and the cu-arxiv VPC (provisioned by arxiv).
This connection includes route tables that map the private IP CIDRs from one
VPC to the other. Note that this works because the private IP CIDRs in the
respective VPCs do not overlap. The connection is also configured to share
private DNS resolution. Shared private resources deployed in the cu-arxiv
VPC are available to both the Kubernetes cluster and on-premises machines.
Note that it is an intentional limitation of AWS Peering Connections that they are non-transitive across DirectConnect. In other words, on-premises machines may not connect to machines in the Kubernetes cluster via DirectConnect and the Peering Connection, nor vice-versa. Such traffic is instead routed through the public internet (see backend gateway, below).
Deploying applications in Kubernetes¶
We use Helm to manage and Kubernetes resources, including deployments, services, and ingress.
The Kubernetes resources used to deploy and operate each respective NG service are packaged as a “chart”. All arXiv-NG charts are housed in the arxiv-k8s repository.
Docker Image Repository¶
We maintain a public Docker image registry at https://hub.docker.com/u/arxiv/. All members of the arXiv dev team should have write access to the repositories in that registry.
Images for new versions of applications are built and pushed by Travis-CI as part of the CI/CD process; see Release process.
New versions of Docker images are deployed by updating the tag on the application deployment resource in Kubernetes (via Helm). See Release process.
Pre-release images (built from the develop branch) are tagged with develop
and with the commit from which it was built. For example,
arxiv/foo:develop and
arxiv/foo:871702d93baee6b62673c26302fd4f4d325b91eb. Pre-release images are
deployed in the staging namespace within the Kubernetes cluster.
Release images (from tags on master branch) are tagged with major, minor,
and micro versions (e.g. arxiv/build:1, arxiv/build:1.3 and
arxiv/build:1.3.2) and the latest tag.
Services¶
Applications are made available to the rest of the cluster by defining a service. Services may be exposed to the outside world via an ingress rule.
Namespaces¶
Separate namespaces
are used to isolate staging and production (default) deployments.
The built-in kube-system namespace is used for infrastructure resources,
such as logging, metrics, and secrets.
Ingress & API gateway¶
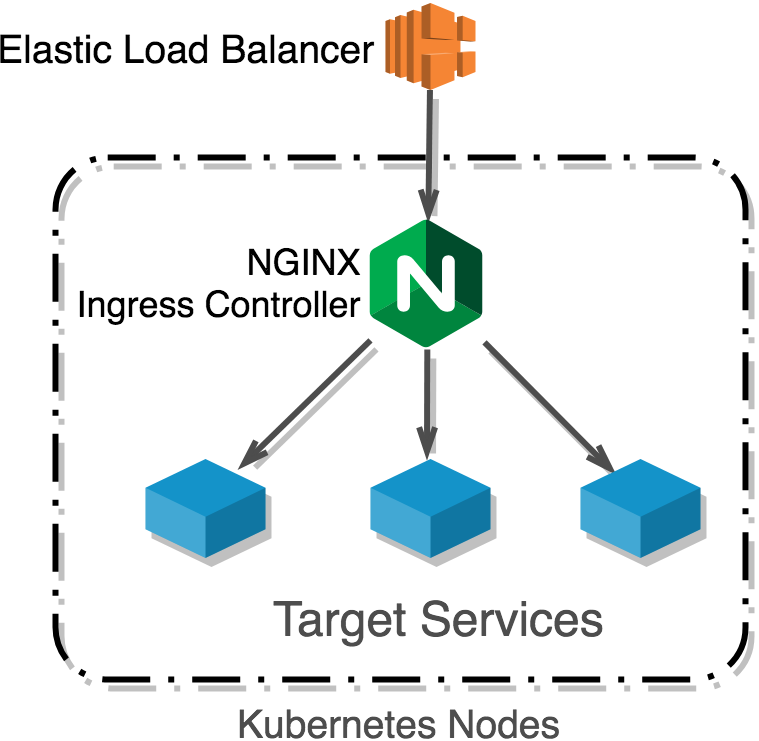
External access to arXiv services is provided via the “ingress” mechanism. Ingress is comprised of two parts: an ingress resource that defines the endpoints that are exposed, and an ingress controller that implements the routing defined by the ingress resource. The ingress resource is created via the Kubernetes API; usually this means that it will be a part of the Helm chart for the particular service.
The ingress controller is a specialized NGINX deployment that sits behind a load balancer. The ingress controller deployment provisions an Elastic Load Balancer that routes external traffic to the services within the cluster.
Kubernetes ingress controller. Kubernetes provisions an Elastic Load Balancer, which proxies requests to an NGINX service running in the cluster. NGINX routes traffic to services based on the ingress rules defined for those services.
We use three different ingress controllers to expose Kubernetes services:
Frontend ingress, which provides the main site at arxiv.org. This uses an L7 ELB with SSL termination.
Backend ingress, which provides access to protected resources to developers, admins, and on-premises systems. This uses L4 ELB, and the NGINX service handles SSL termination and client certificate authentication.
API gateway, which provides access to API consumers at api.arxiv.org. This uses an L7 ELB with SSL termination.
Task queues: AWS Elasticache Redis¶
We use a managed AWS Elasticache service (Redis) as a transport for asynchronous task queues. Redis is an in-memory key-value store. The Celery task system that we use to implement the asynchronous worker pattern utilizes Redis both to provide task queues and to temporarily store the results of task execution.
Services that utilize Redis as a task queue must use a key prefix to avoid collisions with other services (see Celery Configuration).
Logging¶
Access and application logs are aggregated in a central logging facility for posterity, analytics, and reporting. Raw logs from both the legacy and NG clusters are shipped by Filebeat to a Logstash cluster. Logstash parses the raw log messages before depositing them both in Elasticsearch (for analysis) and S3 (for longer-term storage).
Deployment details (including Helm charts) for the logging infrastructure can be found in the arXiv-k8s repository.
arXiv-NG applications should write access, error, and application log messages
to STDOUT/STERR. The Docker engine on each node in the Kubernetes cluster
writes the stdout and stderr from each container to a JSON log file in
/var/lib/docker/containers/.
We use a Filebeat deployed on each node in the cluster to collect logs stored by the Docker engine and ship them to Logstash. A Filebeat process running on the on-premises web nodes also ships logs to Logstash.
Each set of Filebeats ships logs to a separate ingest port on the Logstash service, corresponding to two distinct processing pipelines. Both pipelines generate output to an Elasticsearch cluster and to an S3 bucket.
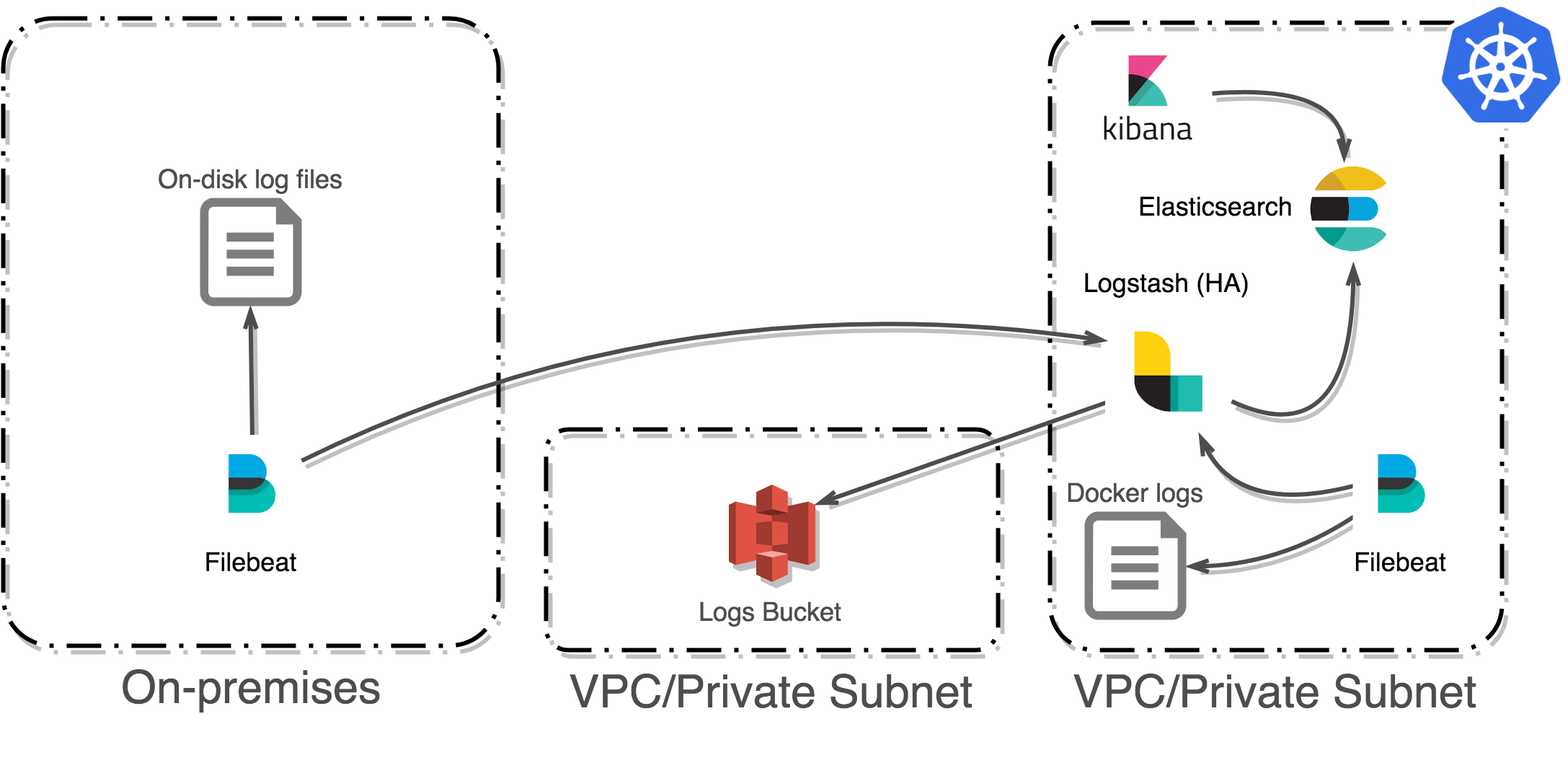
Fig. 24 Overview of the arXiv-NG centralized logging infrastructure.¶
Metrics & Alerting¶
Resource consumption/performance metrics for NG applications and their instances/pods are automatically collected by Kubernetes via cAdvisor.
We use Prometheus to collect cAdvisor metrics. Prometheus runs in the Kubernetes cluster [add ref to chart in arxiv-k8s]. We also run an InfluxDB (time-series database) cluster, into which Prometheus writes metrics data.
Grafana dashboards are used to query and visualize application and cluster performance.
Prometheus alertmanager pushes alerts to the arxiv OpsGenie account, which in turn distributes alerts and notifications to the arXiv dev team.
Scaling¶
Our objective is to keep provisioned resource utilization between 75 and 90%, with the ability to quickly respond to spikes in load without significant degradation of performance from the end-user perspective.
Individual services¶
Deployments of individual applications in Kubernetes are scaled independently by increasing or decreasing the number of pods in the deployment. This is handled by a horizontal pod autoscaler resource; see the Kubernetes docs on pod autoscaling for details. The autoscaler resource for each deployment is defined as part of the Helm chart for that deployment/service.
Cluster resources¶
The cluster as a whole is scaled horizontally by adding and removing nodes (EC2 instances) to/from the cluster. This is performed by a cluster autoscaler controller.